PriorityQueue란 우선순위 큐로써 일반적인 큐의 구조 FIFO(First In First Out)를 가지면서, 데이터가 들어온 순서대로 데이터가 나가는 것이 아닌 우선순위를 먼저 결정하고 그 우선순위가 높은 데이터가 먼저 나가는 자료구조이다.
PriorityQueue를 사용하기 위해선 우선순위 큐에 저장할 객체는 필수적으로 Comparable Interface를 구현해야한다.
Comparable Interface를 구현하면 compareTo method를 override 하게 되고 해당 객체에서 처리할 우선순위 조건을 리턴해주면 PriorityQueue 가 알아서 우선순위가 높은 객체를 추출 해준다.
PriorityQueue는 Heap을 이용하여 구현하는 것이 일반적이다.
데이터를 삽입할 때 우선순위를 기준으로 최대 힙 혹은 최소 힙을 구성하고 데이터를 꺼낼 때 루트 노드를 얻어낸 뒤 루트 노드를 삭제할 때는 빈 루트 노드 위치에 맨 마지막 노드를 삽입한 후 아래로 내려가면서 적절한 자리를 찾아 옮기는 방식으로 진행된다. 최대 값이 우선순위인 큐 = 최대 힙, 최소 값이 우선순위인 큐 = 최소 힙
남은 작업량들의 제곱의 합이 야근 지수기 때문에 가장 높은 야근 지수를 N 시간 만큼 -1 해주면 된다. 우선순위큐는 내부적으로 Queue에서 우선순위가 높은 데이터가 먼저 나가기 때문에 poll 할때마다 가장 높은 데이터가 가장 높은 우선순위로 옮겨진다. 이러한 특징을 이용하여 풀면 아래 코드와 같이 구현할 수 있다.
전체 코드
import java.util.Comparator;
import java.util.PriorityQueue;
class Solution {
public long solution(int n, int[] works) {
long answer = 0;
PriorityQueue<Integer> pq = new PriorityQueue<>(Comparator.reverseOrder());
for (int work : works) {
pq.add(work);
}
while (n > 0) {
int max = pq.poll();
pq.add(--max);
n--;
if(pq.peek() == 0 && n > 0) break;
}
for (Integer num : pq) {
answer += Math.pow(num, 2);
}
if(n != 0) answer = 0;
return answer;
}
}
불량사용자의 조합이 여러가지 나올 수 있기 때문에 중복을 허용하지 않는 set 을 사용하여 불량사용자 조건에 해당되는 user들을 set에 모두 중복, 순서에 상관없이 add 해주는 방법으로 문제를 구현하였다.
유저 아이디(str1)가 불량사용자의 아이디(str2)에 해당이 되는지 검증하여 true/false 로 나타내는 함수이다. 첫번째 if문에서는 길이를 비교하여 길이가 맞지 않으면 false를 return 해주었고, 그아래 코드에선 각 문자를 비교하여 * 이 아니거나 문자열이 일치하지 않는 경우 false를 return 해주었다.
public boolean check(String str1, String str2) {
boolean flag = true;
if (str1.length() != str2.length()) {
flag = false;
return flag;
}
for (int i = 0; i < str1.length(); i++) {
if (str1.charAt(i) != str2.charAt(i) && str2.charAt(i) != '*') {
flag = false;
return flag;
}
}
return flag;
}
여기서 백트래킹 방법으로 HashSet에 다가 해당 되는 userId를 계속 add 해주었다. 유저 수 만큼 for문을 돌려서 해당 유저가 불량 사용자 조건에 해당 되는지를 체크하여 해당된다고 하면 set에 add를 해주었다.
여기서 헷갈렸던 포인트는 DFS(new HashSet<> (set), depth + 1); // 객체 자체를 매개변수로 넘김 DFS(set, depth + 1); // 객체 주소를 매개변수로 넘김
이거에 따라 테스트케이스 3번이 실패하냐 성공하냐로 나뉘었다는 점이었다. 질문하기 게시판에 있는 댓글을 보고 힌트를 얻어 깊은 복사, 얕은 복사 개념 때문이었다는 것을 알게되었고 오늘도 공부할게 정말 많고 갈길이 멀다는 것을 느꼈다.
public void DFS(HashSet<String> set, int depth) {
if (depth == bannedid.length) {
result_set.add(new HashSet<>(set));
return;
}
for (int i = 0; i < userid.length; i++) {
if (set.contains(userid[i]))
continue;
if (check(userid[i], bannedid[depth])) {
set.add(userid[i]);
DFS(new HashSet<> (set), depth + 1);
// DFS(set, depth + 1);
set.remove(userid[i]);
}
}
}
HashSet 안에 HashSet 을 이렇게 선언해준 이유는 불량사용자들의 조합을 Set으로 저장했을 때, 입출력예시 3번 처럼 ["frodo", "fradi", "crodo", "abc123", "frodoc"] ["fr*d*", "*rodo", "******", "******"] 아래 불량유저 조건에 해당되는 조합이 [crodo, abc123, frodo, frodoc] [crodo, abc123, frodo, frodoc] [crodo, abc123, frodo, frodoc] [fradi, abc123, frodo, frodoc] [crodo, abc123, frodo, frodoc] [fradi, abc123, frodo, frodoc] [crodo, abc123, frodo, frodoc] [crodo, fradi, abc123, frodoc] [fradi, abc123, frodo, frodoc] 이런 식으로 5개 나오지만 1,2번과 3,4번은 각각 중복되는 하나의 조합이기 때문에 HashSet에 넣어서 중복을 제거해준 것이다.
HashSet<HashSet<String>> result_set = new HashSet<>();
전체코드
import java.util.*;
class Solution {
static String[] userid;
static String[] bannedid;
static int answer = 0;
HashSet<HashSet<String>> result_set = new HashSet<>();
public int solution(String[] user_id, String[] banned_id) {
userid = user_id;
bannedid = banned_id;
DFS(new HashSet<String>(), 0);
return result_set.size();
}
public void DFS(HashSet<String> set, int depth) {
if (depth == bannedid.length) {
result_set.add(new HashSet<>(set));
return;
}
for (int i = 0; i < userid.length; i++) {
if (set.contains(userid[i]))
continue;
if (check(userid[i], bannedid[depth])) {
set.add(userid[i]);
// new HashSet<> (set) 차이가 뭐지
DFS(new HashSet<> (set), depth + 1);
// DFS(new HashSet<> (), depth + 1);
set.remove(userid[i]);
}
}
}
public boolean check(String str1, String str2) {
boolean flag = true;
if (str1.length() != str2.length()) {
flag = false;
return flag;
}
for (int i = 0; i < str1.length(); i++) {
if (str1.charAt(i) != str2.charAt(i) && str2.charAt(i) != '*') {
flag = false;
return flag;
}
}
return flag;
}
}
Cloneable 인터페이스는 복제해도 되는 클래스임을 명시하는 용도의 믹스인 인터페이스지만, 아쉽게도 의도한 목적을 제대로 이루지 못했다. 여기서 큰 문제점은 clone 메서드가 선언된 곳이 Cloneable이 아닌 OBject이고, 그 마저도 protected이다. 그래서 Cloneable을 구현하는 것만으로는 외부 객체에서 clone 메소드를 호출할 수 없다. 리플렉션을 사용하면 가능하지만, 100% 성공하는 것도 아니다.
이러한 여러 문제점을 가진 인터페이스이지만, Cloneable 방식은 널리 쓰이고 있어서 잘 알아두는 것이 좋다.
Cloneable이 몰고 온 모든 문제를 되짚어봤을 때, 새로운 인터페이스를 만들 때는 절대 Cloneable을 확장해서는 안 되며, 새로운 클래스도 이를 구현해서는 안된다. final 클래스라면 Cloneable을 구현해도 위험이 크지는 않지만, 성능 최적화 관점에서 검토한 후 별다른 문제가 없을 때만 드물게 허용해야 한다.
기본 원칙은 '복제 기능은 생성자와 팩터리를 이용하는게 최고' 라는 것이다.
단, 배열만은 clone 메소드 방식이 가장 깔끔한, 이 규칙의 합당한 예외라 할 수 있다.
public class CopyObject {
private String name;
private int age;
public CopyObject() {
}
/* 복사 생성자 */
public CopyObject(CopyObject original) {
this.name = original.name;
this.age = original.age;
}
/* 복사 팩터리 */
public static CopyObject copy(CopyObject original) {
CopyObject copy = new CopyObject();
copy.name = original.name;
copy.age = original.age;
return copy;
}
public CopyObject(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
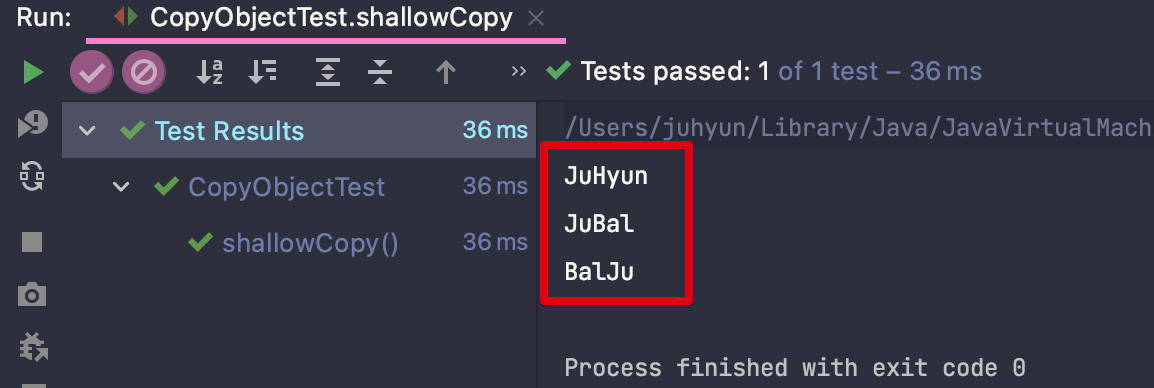
@Test
void shallowCopy() {
CopyObject original = new CopyObject("JuHyun", 20);
CopyObject copyConstructor = new CopyObject(original);
CopyObject copyFactory = CopyObject.copy(original);
copyConstructor.setName("JuBal");
copyFactory.setName("BalJu");
System.out.println(original.getName());
System.out.println(copyConstructor.getName());
System.out.println(copyFactory.getName());
}
복사 생성자와 복사 팩터리를 통해 객체를 복사하는 과정도 깊은 복사임을 알 수 있습니다.
깊은 복사를 그림으로 나타내면 다음과 같습니다.
얕은 복사와는 다르게 Heap 영역에 새로운 메모리 공간을 생성하여 실제 값을 복사합니다.
Collections나 Map의 경우 이미 복사 팩터리인 copy() 메소드를 구현하고 있습니다.
/**
* Copies all of the elements from one list into another. After the
* operation, the index of each copied element in the destination list
* will be identical to its index in the source list. The destination
* list's size must be greater than or equal to the source list's size.
* If it is greater, the remaining elements in the destination list are
* unaffected. <p>
*
* This method runs in linear time.
*
* @param <T> the class of the objects in the lists
* @param dest The destination list.
* @param src The source list.
* @throws IndexOutOfBoundsException if the destination list is too small
* to contain the entire source List.
* @throws UnsupportedOperationException if the destination list's
* list-iterator does not support the {@code set} operation.
*/
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD ||
(src instanceof RandomAccess && dest instanceof RandomAccess)) {
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
} else {
ListIterator<? super T> di=dest.listIterator();
ListIterator<? extends T> si=src.listIterator();
for (int i=0; i<srcSize; i++) {
di.next();
di.set(si.next());
}
}
}
public static void DFS(String str, StringBuilder sb, int start_idx, int current_idx, int course_len) {
if (current_idx == course_len) {
map.put(sb.toString(), map.getOrDefault(sb.toString(), 0) + 1);
return;
}
for (int i = start_idx; i < str.length(); i++) {
sb.append(str.charAt(i));
DFS(str, sb, i + 1, current_idx + 1, course_len);
sb.delete(current_idx, current_idx + 1);
}
}
orders 배열에 저장되 있는 str 변수를 course ( ex : 2,3,4.. ) 크기 만큼 자를수 있게 구현한 백트래킹 함수입니다. start_idx 변수는 DFS 함수 내에서 잘랐 을때 시작 기준이 되는 인덱스를 의미하고 current_idx 변수는 시작기준이 되서 course_len 만큼 잘려나가는 도중에 현재 얼만큼 StringBuilder에 누적되서 잘려있냐를 의미하는 인덱스 변수입니다. course_len 변수는 course 배열에 저장된 값을 입력받아 해당 크기만큼 조합의 경우의 수를 구하게 하는 변수입니다.
for (int i = 0; i < orders.length; i++) {
char[] charArr = orders[i].toCharArray();
Arrays.sort(charArr);
orders[i] = String.valueOf(charArr);
}
여기서 String 배열을 toCharArray를 통해 다시 오름차순으로 재정렬 해준 이유는 입출력 예 3번 처럼 ["XYZ", "XWY", "WXA"]를 입력받는 경우 WX, XW 가 같은 메뉴 이지만 순서가 다름에 따라 다른 메뉴로 분류되기 때문에 이를 오름차순으로 정렬해줌으로서 순열(N에서 R을 골랐을 때 순서가 상관있는 경우의 수)이 아니라 조합(N에서 R을 골랐을 때, 순서가 상관없는 경우의 수 )으로 순서가 상관없게 만들기 위함입니다.
for (int i = 0; i < course.length; i++) {
map = new HashMap<>();
int max = Integer.MIN_VALUE;
for (int j = 0; j < orders.length; j++) {
StringBuilder sb = new StringBuilder();
DFS(orders[j], sb, 0, 0, course[i]);
}
for (String key : map.keySet()) {
if (map.get(key) >= 2 && map.get(key) >= max) {
max = Math.max(map.get(key), max);
}
}
for (String key : map.keySet()) {
if (max == map.get(key)) {
al.add(key);
}
}
Collections.sort(al);
}
메뉴 조합을 Key에 저장하고, 메뉴 조합의 카운트 (그 메뉴가 몇번 주문되었는지)를 Value에 저장하여 각 메뉴가 모두 주문되고 카운트가 끝났을 때 (DFS 함수가 종료되었을 때) 메뉴 주문이 2번이상이고, 그중에 가장 주문량이 많은 메뉴의 주문량을 max 변수에 저장하였습니다. 그렇게 저장된 max 변수만큼 주문이 들어온 메뉴를 ArrayList 에 저장하여 Collections.sort(al) 함수를 통해 다시 오름차순으로 재정렬하여 출력하였습니다
전체 코드
import java.util.*;
class Solution {
static HashMap<String, Integer> map;
public ArrayList<String> solution(String[] orders, int[] course) {
ArrayList<String> al = new ArrayList<>();
for (int i = 0; i < orders.length; i++) {
char[] charArr = orders[i].toCharArray();
Arrays.sort(charArr);
orders[i] = String.valueOf(charArr);
}
for (int i = 0; i < course.length; i++) {
map = new HashMap<>();
int max = Integer.MIN_VALUE;
for (int j = 0; j < orders.length; j++) {
StringBuilder sb = new StringBuilder();
DFS(orders[j], sb, 0, 0, course[i]);
}
for (String key : map.keySet()) {
if (map.get(key) >= 2 && map.get(key) >= max) {
max = Math.max(map.get(key), max);
}
}
for (String key : map.keySet()) {
if (max == map.get(key)) {
al.add(key);
}
}
Collections.sort(al);
}
return al;
}
public static void DFS(String str, StringBuilder sb, int start_idx, int current_idx, int course_len) {
if (current_idx == course_len) {
map.put(sb.toString(), map.getOrDefault(sb.toString(), 0) + 1);
return;
}
for (int i = start_idx; i < str.length(); i++) {
sb.append(str.charAt(i));
DFS(str, sb, i + 1, current_idx + 1, course_len);
sb.delete(current_idx, current_idx + 1);
}
}
}
조합이란 n 개의 숫자 중에서 r 개의 수를 순서 없이 뽑는 경우를 말한다. 예를 들어 [1, 2, 3] 이란 숫자 배열에서 2개의 수를 순서 없이 뽑으면
[1, 2]
[1, 3]
[2, 3]
이렇게 3 개가 나온다. (순열과 다르게 [2, 1] [3, 1] [3, 2] 등은 중복이라서 된다) 여러 가지 방법이 있지만 핵심은
배열을 처음부터 마지막까지 돌며 1. 현재 인덱스를 선택하는 경우 2. 현재 인덱스를 선택하지 않는경우 이렇게 두가지로 모든 경우를 완전 탐색해주면 된다.
| 백트래킹을 이용한 조합(Combination) 알고리즘
start 변수는 기준입니다. start 인덱스를 기준으로 start 보다 작으면 뽑을 후보에서 제외, start 보다 크면 뽑을 후보가 됩니다. 예를 들어 [1, 2, 3] 배열이 있고 start 가 0 부터 시작합니다. 함수에 들어오면 먼저 i 가 start 부터 시작하는 for 문에 들어갑니다. 만약 0 인덱스인 1을 뽑는다면 visited[i] 는 true 가 되고 뽑지 않는다면 visited[i] 는 false 입니다. 1을 선택한 경우와 선택하지 않은 경우 둘 다 봐야합니다. 하지만 더이상 1은 고려 대상이 아니기 때문에 다음 for 문은 무조건 i+1 부터 시작해주어야 합니다.
코드
// 백트래킹 사용
// 사용 예시 : combination(arr, visited, 0, n, r)
static void combination(int[] arr, boolean[] visited, int start, int n, int r) {
if(r == 0) {
print(arr, visited, n);
return;
}
for(int i=start; i<n; i++) {
visited[i] = true;
combination(arr, visited, i + 1, n, r - 1);
visited[i] = false;
}
}
결과
[4 개 중에서 1 개 뽑기]
1
2
3
4
[4 개 중에서 2 개 뽑기]
1 2
1 3
1 4
2 3
2 4
3 4
[4 개 중에서 3 개 뽑기]
1 2 3
1 2 4
1 3 4
2 3 4
[4 개 중에서 4 개 뽑기]
1 2 3 4
| 재귀을 이용한조합(Combination) 알고리즘
depth 변수를 사용합니다. depth 변수는 현재 인덱스라고 생각하면 됩니다. 현재 인덱스를 뽑는다면 visited[depth] = true 뽑지 않는다면 visited[depth] = false 이렇게 진행하면 됩니다. 역시 마찬가지로 뽑은 경우와 뽑지 않은 경우 모두 봐야하고, 그 때 이전에 본 값들은 더이상 고려 대상이 아니기 때문에 depth 은 무조건 1 씩 증가합니다. depth == n 이 되면 모든 인덱스를 다 보았으므로 재귀를 종료합니다.
코드
// 재귀 사용
// 사용 예시 : comb(arr, visited, 0, n, r)
static void comb(int[] arr, boolean[] visited, int depth, int n, int r) {
if (r == 0) {
print(arr, visited, n);
return;
}
if (depth == n) {
return;
}
visited[depth] = true;
comb(arr, visited, depth + 1, n, r - 1);
visited[depth] = false;
comb(arr, visited, depth + 1, n, r);
}
결과
[4 개 중에서 1 개 뽑기]
1
2
3
4
[4 개 중에서 2 개 뽑기]
1 2
1 3
1 4
2 3
2 4
3 4
[4 개 중에서 3 개 뽑기]
1 2 3
1 2 4
1 3 4
2 3 4
[4 개 중에서 4 개 뽑기]
1 2 3 4
전체 소스코드
/**
* 조합 : n 개 중에서 r 개 선택
*/
public class Combination {
public static void main(String[] args) {
int n = 4;
int[] arr = {1, 2, 3, 4};
boolean[] visited = new boolean[n];
for (int i = 1; i <= n; i++) {
System.out.println("\n" + n + " 개 중에서 " + i + " 개 뽑기");
comb(arr, visited, 0, n, i);
}
for (int i = 1; i <= n; i++) {
System.out.println("\n" + n + " 개 중에서 " + i + " 개 뽑기");
combination(arr, visited, 0, n, i);
}
}
// 백트래킹 사용
// 사용 예시 : combination(arr, visited, 0, n, r)
static void combination(int[] arr, boolean[] visited, int start, int n, int r) {
if (r == 0) {
print(arr, visited, n);
return;
}
for (int i = start; i < n; i++) {
visited[i] = true;
combination(arr, visited, i + 1, n, r - 1);
visited[i] = false;
}
}
// 재귀 사용
// 사용 예시 : comb(arr, visited, 0, n, r)
static void comb(int[] arr, boolean[] visited, int depth, int n, int r) {
if (r == 0) {
print(arr, visited, n);
return;
}
if (depth == n) {
return;
}
visited[depth] = true;
comb(arr, visited, depth + 1, n, r - 1);
visited[depth] = false;
comb(arr, visited, depth + 1, n, r);
}
// 배열 출력
static void print(int[] arr, boolean[] visited, int n) {
for (int i = 0; i < n; i++) {
if (visited[i]) {
System.out.print(arr[i] + " ");
}
}
System.out.println();
}
}
defaultValue : 지정된 키로 매핑된 값이 없는 경우 반환되어야 하는 기본값입니다.
반환 값 : 찾는 key가 존재하면 해당 key에 매핑되어 있는 값을 반환하고, 그렇지 않으면 디폴트 값이 반환됩니다.
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<String, Integer> hm = new HashMap<>();
for(int i = 0; i < 5; i++){
hm.put("A", hm.getOrDefault("A", 0) + 1);
System.out.println(hm.get("A"));
}
}
}
해쉬맵을 사용할 때, 키값이 존재하면 매핑되어있는 값을 반환한다는 특징을 통해서 value 가 키값의 카운트 값을 의미하는 경우 우 +1 을 해서 다시 put 해줌으로서 저렇게 활용할 수 있다. 알고리즘 풀 때 자주 응용된다.
카카오 기출에서 단순 구현문제가 많은 것 같다. 문제만 잘 읽고 이해하면 구현하는 것은 어렵지 않지만 문제 읽고 이해하는거 자체가 어려운 편이다.. (개인적인 생각) 이번 문제도 마찬가지로 재귀를 이용한 구현문제이다.
문제 포인트
문제 그대로 u와 v를 분리하여 그대로 수행해주면 된다. 필자는 처음에 분리를 해야된다는 단순한 생각때문에 함수 자체에서 String[] 로 나누어서 구분해야되나 생각했었는데, 그럴 필요가 전혀 없이 DFS 함수에서 return 할 때 각 if문에 들어가는 조건대로 String으로 return 해주면 되는 방법이 있었다..
import java.util.*;
class Solution {
public String solution(String p) {
String answer = "";
answer = DFS(p);
return answer;
}
// u, v를 분리하는 함수
public String DFS(String str) {
if (str.equals(""))
return "";
String u = "";
String v = "";
int cnt = 0;
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) == '(')
cnt++;
else if (str.charAt(i) == ')')
cnt--;
u += str.charAt(i);
if (cnt == 0) {
v = str.substring(i + 1, str.length());
break;
}
}
if (check(u)) {
return u += DFS(v);
} else {
StringBuilder sb = new StringBuilder();
sb.append("(");
sb.append(DFS(v));
sb.append(")");
u = u.substring(1, u.length() - 1);
for (int i = 0; i < u.length(); i++) {
if (u.charAt(i) == '(')
sb.append(')');
else if (u.charAt(i) == ')')
sb.append('(');
}
return sb.toString();
}
}
// 올바른 괄호 문자열인지 판단하는 함수
public boolean check(String str) {
Stack<Character> stack = new Stack<>();
boolean flag = true;
for (int i = 0; i < str.length(); i++) {
char tmp = str.charAt(i);
if (tmp == '(') {
stack.push('(');
} else if (tmp == ')') {
if (stack.isEmpty()) {
flag = false;
break;
}
if (stack.peek() == '(')
stack.pop();
}
}
if (!stack.isEmpty())
flag = false;
return flag;
}
}
문제가 엄청 길어서 쫄았지만, 단순한 구현 문제였다. 1. 문자열로 주어진 시간을 분으로 환산 2. 한번에 StringBuilder 에 넣을수 있도록 음계를 C# -> c 이런식으로 모두 변환 3. sheet_music.charAt(j % sheet_music.length()) charAt의 인덱스를 저렇게 나머지를 통해 구함 4. 라디오에서 재생된 시간이 제일 긴 음악이 반환되도록 max_play_time 변수를 선언하여 최대값이 초기화 될때 answer 에 저장
class Solution {
public String solution(String m, String[] musicinfos) {
String answer = "(None)";
int max_play_time = Integer.MIN_VALUE;
for(int i = 0; i < musicinfos.length; i++){
String tmp[] = musicinfos[i].split(",");
StringBuilder sb = new StringBuilder();
int start_time = cal_time(tmp[0]);
int end_time = cal_time(tmp[1]);
String music_title = tmp[2];
String sheet_music = tmp[3];
int play_time = end_time - start_time;
// #이 붙은 음을 소문자 음으로 치환
sheet_music = change_melody(sheet_music);
// (재생시간 / 악보의 길이)를 나눴을 때 나오는 악보의 인덱스값을 append
for(int j = 0; j < play_time ; j++)
sb = sb.append(sheet_music.charAt(j % sheet_music.length()));
if(sb.toString().contains(change_melody(m))){
// 조건이 일치하는 음악이 여러 개일 때에는 라디오에서 재생된 시간이 제일 긴 음악 제목을 반환해야 하므로 max_play_time < play_time
if(max_play_time < play_time){
max_play_time = play_time;
answer = music_title;
}
}
}
return answer;
}
public int cal_time(String time){
String tmp[] = time.split(":");
return Integer.parseInt(tmp[0]) * 60 + Integer.parseInt(tmp[1]);
}
public String change_melody(String str){
str = str.replaceAll("A#","a");
str = str.replaceAll("C#","c");
str = str.replaceAll("D#","d");
str = str.replaceAll("F#","f");
str = str.replaceAll("G#","g");
return str;
}
}
DFS를 사용해서 몇번 순환 하는지 체크하는 어렵지 않은 문제였다. computers 배열에서 computers[i][i] 인 경우 1로 초기화가 되있기 때문에 모두 0으로 바꾸어 주고, 1이거나 방문하지 않았던 컴퓨터를 계속 DFS로 방문하여 몇번 싸이클이 도는지 answer 변수에 추가해주면 되는 단순한 DFS 문제였다.
DFS 함수안에서 if(visited[i]) return; 하는 경우와 (보통 백트래킹) visited[i] = true; 이런 경우를 잘 구분해서 사용해야 할 것 같다.
class Solution {
static int N;
static boolean[] visited;
public int solution(int n, int[][] computers) {
int answer = 0;
N = n;
visited = new boolean[N];
for (int i = 0; i < N; i++)
computers[i][i] = 0;
for (int i = 0; i < N; i++) {
if (!visited[i]) {
DFS(i, computers);
answer++;
}
}
return answer;
}
public void DFS(int n, int[][] computers) {
visited[n] = true;
for (int i = 0; i < N; i++) {
if (!visited[i] && computers[n][i] == 1) {
DFS(i, computers);
}
}
}
}
문제 푸는 방식을 찾아내는 것이 핵심이었던 문제였다. 구현하는 시간보다 문제를 어떻게 풀어야될지에 대한 생각을 하는데 시간을 더 많이 소요 했던거 같다.
이번 문제의 핵심은 백트레킹 (BackTraking) 을 사용하여 가능할 수 있는 모든 경로를 ArrayList<String> 에 저장하는 것
- 가능한 경로가 2개 이상일 경우 알파벳 순서가 앞서가는 경로를 return 해줘야 하기 때문에 Collections.sort(list)를 사용해서 ArrayList 에 추가된 String 값을 알파벳 순서로 재배열 한뒤 첫번째 인덱스에 저장된 String 값 return - visited[i] = true 로 방문체크를 하고 DFS 함수를 빠져나오면서 다시 visited[i] = false 를 해주기 때문에 같은 출발지에서 여러 도착지로, 즉 중복된 출발지에서 도착지가 달라도 모든 경로를 탐색할 수 있게 한다.
import java.util.*;
class Solution {
static boolean visited[];
static ArrayList<String> list = new ArrayList<String>();
public String[] solution(String[][] tickets) {
String[] answer = {};
visited = new boolean[tickets.length+1];
DFS("ICN", "ICN", 0, tickets);
Collections.sort(list);
return list.get(0).split(" ");
}
public void DFS(String start, String path, int depth, String tickets[][]) {
if (depth == tickets.length){
list.add(path);
return;
}
for (int i = 0; i < tickets.length; i++) {
if (tickets[i][0].equals(start) && !visited[i]) {
visited[i] = true;
DFS(tickets[i][1], path + " " + tickets[i][1], depth + 1, tickets);
visited[i] = false;
}
}
}
}