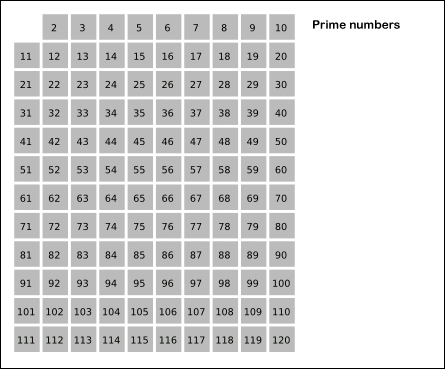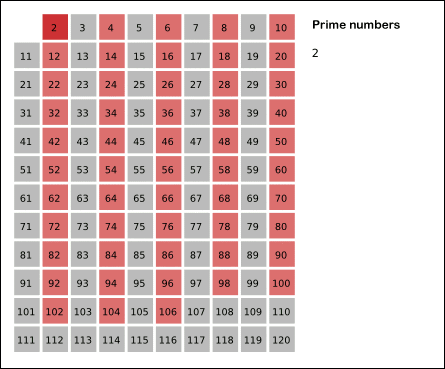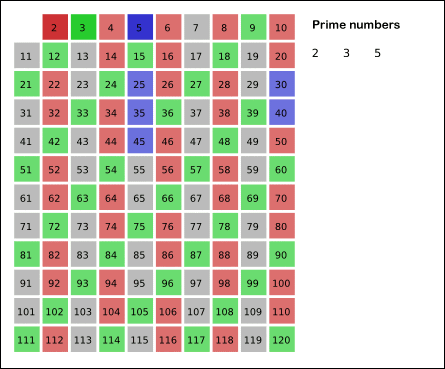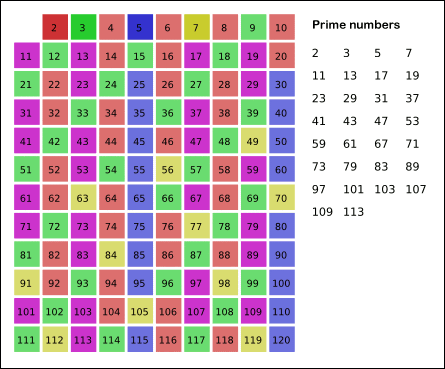
직관적이어서 가장 많이 사용할 듯한 위의 예제에서 "hello" 값을 가지고 있던 String 클래스의 참조변수 str이 가리키는 곳에 저장된 "hello"에 "world" 문자열을 더해 "hello world"로 변경한 것으로 착각할 수 있습니다.
하지만 기존에 "hello" 값이 들어가있던 String 클래스의 참조변수 str이 "hello world"라는 값을 가지고 있는 새로운 메모리영역을 가리키게 변경되고 처음 선언했던 "hello"로 값이 할당되어 있던 메모리 영역은 Garbage로 남아있다가 GC(garbage collection)에 의해 사라지게 되는 것 입니다. String 클래스는 불변하기 때문에 문자열을 수정하는 시점에 새로운 String 인스턴스가 생성된 것이지요.
위와 같이 String은 불변성을 가지기 때문에 변하지 않는 문자열을 자주 읽어들이는 경우 String을 사용해 주시면 좋은 성능을 기대할 수 있습니다. 그러나 문자열 추가,수정,삭제 등의 연산이 빈번하게 발생하는 알고리즘에 String 클래스를 사용하면 힙 메모리(Heap)에 많은 임시 가비지(Garbage)가 생성되어 힙메모리가 부족으로 어플리케이션 성능에 치명적인 영향을 끼치게 됩니다. (+연산에 내부적으로 char배열을 사용함)
이를 해결하기 위해 Java에서는 가변(mutable)성을 가지는 StringBuffer / StringBuilder 클래스를 도입했습니다.
String 과는 반대로 StringBuffer/StringBuilder 는 가변성 가지기 때문에 .append() .delete() 등의 API를 이용하여 동일 객체내에서 문자열을 변경하는 것이 가능합니다. 따라서 문자열의 추가,수정,삭제가 빈번하게 발생할 경우라면 String 클래스가 아닌 StringBuffer/StringBuilder를 사용하셔야 합니다.
StringBuffer sb= new StringBuffer("hello");
sb.append(" world");
| StringBuffer vs StringBuilder
그렇다면 동일한 API를 가지고 있는 StringBuffer, StringBuilder의 차이점은 무엇일까요?
가장 큰 차이점은 동기화의 유무로써 StringBuffer는 동기화 키워드를 지원하여 멀티쓰레드 환경에서 안전하다는 점(thread-safe) 입니다. 참고로 String도불변성을 가지기때문에 마찬가지로 멀티쓰레드 환경에서의 안정성(thread-safe)을 가지고 있습니다.
반대로 StringBuilder는 동기화를 지원하지 않기때문에 멀티쓰레드 환경에서 사용하는 것은 적합하지 않지만 동기화를 고려하지 않는 만큼 단일쓰레드에서의 성능은 StringBuffer 보다 뛰어납니다.
| 정리
마지막으로 각 클래스별 특징을 정리해 보겠습니다. 컴파일러에서 분석 할때 최적화에 따라 다른 성능이 나올 수도 있지만 일반적인 경우에는 아래와 같은 경우에 맞게 사용하시면 될 것 같네요.
String : 문자열 연산이 적고 멀티쓰레드 환경일 경우
StringBuffer : 문자열 연산이 많고 멀티쓰레드 환경일 경우
StringBuilder : 문자열 연산이 많고 단일쓰레드이거나 동기화를 고려하지 않아도 되는 경우
String, StringBuffer, StringBuilder 비교
* StringBuffer와 StringBuilder는 성능으로 따졌을 때 2배의 속도차이가 있다고 하지만 참고사이트의 속도 차이 실험 결과 append()연산이 약 1억6천만번 일어날 때 약 2.6초의 속도차이를 보인다고 합니다.
(String은 +연산이 16만번이상 넘어가게 되면 10초이상 걸리면서 못 쓸정도의 성능을 보입니다.)
따라서 문자열연산이 많지만 엄청나게 일어나지 않는 환경이라면 StringBuffer를 사용해서 thread-safe한 것이 좋다는 생각입니다.
* JDK1.5이상부터 String에서 +연산으로 작성하더라도 StringBuilder로 컴파일하게 만들어 놨다지만 여전히 String클래스의 객체 생성하는 부분을 동일하므로 StringBuffer,StringBuilder 사용이 필요함.
+ StringBuffer, StringBuilder의 경우 buffer size를 초기에 설정해야하는데 이런 생성, 확장 오버로드가 걸려 버퍼사이즈를 잘못 초기화할 경우 성능이 좋지 않을 수 있음.
+ String클래스가 컴파일러분석단계에서 최적화될 가능성이 있기때문에 간혹 성능이 잘나오는 경우도 있음. 문자열 연산이 많지 않은 경우는 그냥 사용해도 무방.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
static int N;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
for (int i = 2; i <= Math.sqrt(N); i++) {
while (N % i == 0) {
System.out.println(i);
N /= i;
}
}
if (N != 1)
System.out.println(N);
}
}
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Collections;
public class Main {
static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
M = Integer.parseInt(br.readLine());
ArrayList<Integer> al = new ArrayList<Integer>();
int sum = 0;
for (int i = N; i <= M; i++) {
boolean flag = true;
if(i == 1)
continue;
for (int j = 2; j <= Math.sqrt(i); j++) {
if (i % j == 0) {
flag = false;
break;
}
}
if (flag) {
sum += i;
al.add(i);
}
}
Collections.sort(al);
if(al.isEmpty()) {
System.out.println("-1");
}
else {
System.out.println(sum);
System.out.println(al.remove(0));
}
}
}
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static int N;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
int number = 0;
int count = 0;
for (int i = 0; i < N; i++) {
number = Integer.parseInt(st.nextToken());
if (number == 1)
continue;
boolean flag = true;
for (int j = 2; j <= Math.sqrt(number); j++) {
if (number % j == 0) {
flag = false;
break;
}
}
if (flag) {
count++;
}
}
System.out.println(count);
}
}
우리는 앞서 조화수를 통해 점근적 시간 복잡도 O(NlogN) 이라는 시간 복잡도를 얻었다.
이 의미는 x개의 수에 대해 2일 때 체크하는 개수인 (x/2), 3일 때 체크하는 개수인 (x/3), ... 이렇게 체크를 하게 된다.
하지만 우리가 알고싶은 것은 이미중복되는 수들은 검사하지 않는다는 것이다. 이 의미는 무엇일까? 결국 검사하는 수는 소수로 판정 될 때 그의 배수들을 지우는 것이라는 것이다. 이 말은 구간 내의 소수의 개수를 알아야 한다는 뜻이기도 하다.
근데, 소수가 규칙성이 있는가? 이 것은 아직까지도 풀지못한 것이다. 이를 찾고자 가우스는 15살 때 하나하나씩 구하면서 x보다 작거나 같은 소수의 밀도에 대해 대략1 / ln(x)라는 것을 발견하게 되는데 증명을 못했다. (이를가우스의 소수 정리라고 한다)
즉, 위를 거꾸로 말하면 x번째 소수는 xlog(x) 라는 의미가 되지 않겠는가? 즉, 우리는 앞서 1/x 의 합을 구했지만, 실제로 중복되는 수가 제외된다면 x는 소수만 된다는 의미고, 이는 소수의 역수 합이다. (1/2 + 1/3 + 1/5 + 1/7 + ⋯ ) 이런식으로 말이다.
월드전자는 노트북을 제조하고 판매하는 회사이다. 노트북 판매 대수에 상관없이 매년 임대료, 재산세, 보험료, 급여 등 A만원의 고정 비용이 들며, 한 대의 노트북을 생산하는 데에는 재료비와 인건비 등 총 B만원의 가변 비용이 든다고 한다.
예를 들어 A=1,000, B=70이라고 하자. 이 경우 노트북을 한 대 생산하는 데는 총 1,070만원이 들며, 열 대 생산하는 데는 총 1,700만원이 든다.
노트북 가격이 C만원으로 책정되었다고 한다. 일반적으로 생산 대수를 늘려 가다 보면 어느 순간 총 수입(판매비용)이 총 비용(=고정비용+가변비용)보다 많아지게 된다. 최초로 총 수입이 총 비용보다 많아져 이익이 발생하는 지점을 손익분기점(BREAK-EVEN POINT)이라고 한다.
A, B, C가 주어졌을 때, 손익분기점을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 A, B, C가 빈 칸을 사이에 두고 순서대로 주어진다. A, B, C는 21억 이하의 자연수이다.
출력
첫 번째 줄에 손익분기점 즉 최초로 이익이 발생하는 판매량을 출력한다. 손익분기점이 존재하지 않으면 -1을 출력한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static int A,B,C,N;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
A = Integer.parseInt(st.nextToken());
B = Integer.parseInt(st.nextToken());
C = Integer.parseInt(st.nextToken());
if(C-B>0) {
N = (A / (C-B)) +1;
} else {
N = -1;
}
System.out.println(N);
}
}