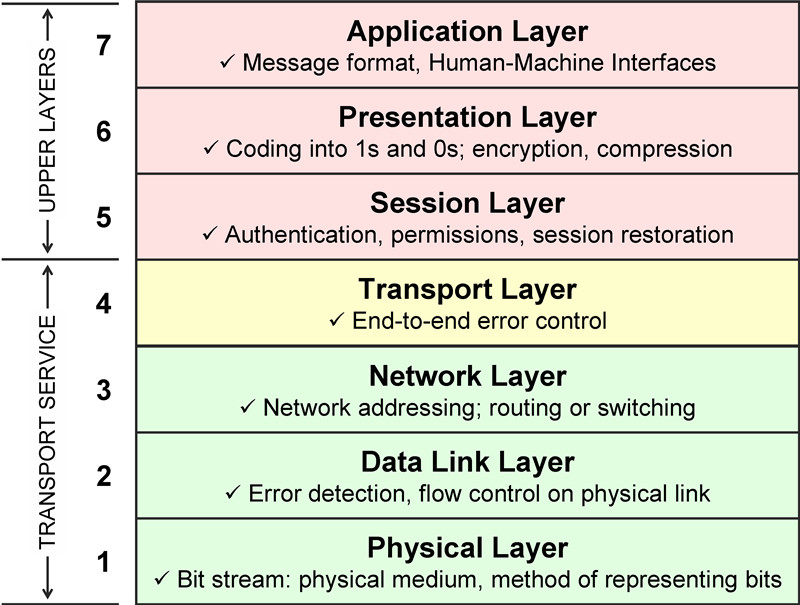
데이터베이스(DataBase, DB)는 여러 사람들이 공유하고 사용할 목적으로 통합 관리되는 정보의 집합이다. 은행, 예약, 검색, 쇼핑 등 일상 속에서 이용하고 있는 많은 온라인 서비스들에서 DB를 활용한다. 과거에는 숫자와 문자 정보 중심의 DB가 많이 쓰였으나 시간이 지남에 따라 멀티미디어 데이터까지도 관리하는 수준으로 발전하였다. (라고는 하지만 blob 데이터를 DB에 두는 것 외에는 실제로 일을 하면서 데이터베이스에 멀티미디어 데이터를 관리하는 것을 본 적은 없다.)
DB는 반드시 데이터베이스 관리 시스템(DataBase Management System, DBMS)과 함께 한다. DB 자체는 관련성 있는 데이터의 모음이고, 실제로 우리는 그 모음을 잘 다룰 수 있도록 도와주는 시스템인 DBMS를 통해 DB를 사용한다. 관계형 DB(Relational DataBase, RDB)를 관리해주는 RDBMS가 오랜 기간 동안 시장을 지배하고 있고, 차세대 DB로 NoSQL DB가 쓰이고 있다.
이 글에서는 전통적인 DB 강의에서 주로 다루는 RDB를 위주로 쓰여있다. DB와 DBMS를 사용하는 측면에서의 이야기를 진행한 뒤, 사용을 넘어서 DB를 만들기 위해서는 어떤 것들을 알아야 하는지에 대해 살펴볼 것이다.
데이터베이스 사용 관점 개요
DB는 관련 있는 데이터를 모아놓은 것이다. 실제 데이터와, 그 데이터에 대한 정보를 모아 놓은 메타 데이터로 이루어져 있다. 말하자면 데이터들을 모아놓은 파일과 같은 것이다. 어떤 경우에는 복잡하게 DB를 사용하지 않고 직접 파일로 관리하는 것이 더 편할지 모르지만, 많은 경우에 데이터를 효율적으로 관리하거나 접근 관리 등 여러 가지 추가적인 기능들이 필요하기 때문에 DB를 쓰게 된다.
DB에서 원하는 데이터를 가져올 때는 직접 DB에 접근하지 않고 DBMS에게 질의(Query)하게 된다. 컴퓨터 프로그램을 만들기 위해서 프로그래밍 언어가 있듯 DBMS에게 질의하기 위해 SQL이라는 언어를 사용한다. DBMS는 입력된 SQL을 처리하고 필요하다면 DB에 접근하여 작업을 수행한다.
대부분의 RDB에서는 질의를 처리하는 것 외에도 View, 데이터 무결성 제약(Data Integrity Contraints), Trigger, 권한 관리(Authorization) 등 기능을 제공한다. 사용자는 이러한 기능들을 바탕으로 DB를 좀 더 편리하게 이용할 수 있게 된다.
DB는 구조화된 데이터를 저장한다. 따라서, 현실 세계의 데이터를 DB에 저장하기 위해 모델링을 해야 한다. RDB에서는 이름에도 관계형이라는 말이 들어가듯 보통 개체-관계 모델링(Entity-Relationship Modelling, ERD) 방법으로 데이터를 구조화한다. 이러한 모델링 작업을 DB 설계라고 한다.
중복된 데이터가 존재하면 DB를 관리하는 과정에서 이상이 생길 수 있다. DB를 설계할 때 이러한 문제가 아예 일어나지 않게끔 한다면 더 좋을 것이다. 함수 종속성을 확인하면 어떤 이상(Anomaly)이 존재할지 알 수 있으며, 함수 종속성을 없애기 위해 구조를 변경하는 작업을 정규화(Normalization)이라고 한다. 과도한 정규화는 성능 문제를 야기할 수 있기 때문에 상황에 따라 적절한 타협을 해야 하는 경우도 생길 것이다.
데이터베이스 스키마
데이터베이스 스키마(Database schema)는 DB에서 데이터의 구조, 데이터의 표현 방법, 데이터 간의 관계를 형식 언어로 정의한 구조이다. 널리 쓰이는 3단계 스키마 구조에서는 DB를 관점에 따라 외부 스키마, 개념 스키마, 내부 스키마 3단계로 나뉜다. 외부 스키마에서는 각 사용자의 관점에 대해 보는 것이고, 개념 스키마에서는 모든 사용자의 관점으로 보는 것이며, 내부 스키마는 물리적으로 DB에 접근하는 관점으로 보는 것이다. 이는 추상화와 비슷한데, 각 단계를 분리함으로써 논리적/물리적 독립성을 얻게 된다. 좀 더 알고 싶다면 다음 링크를 참고.
 출처 : https://www.spinellis.gr/etech/db/abstr.htm
출처 : https://www.spinellis.gr/etech/db/abstr.htm
관계형 데이터 모델
관계 모델에서는 이론적으로 DB를 관계(Relation)의 집합으로, 관계를 행(Tuple)의 집합으로, 행을 속성(Attribute)의 집합으로 본다. RDB에서는 관계가 테이블(Table), 행이 레코드(Record), 속성이 컬럼(Column)으로 대치된다. 관계라는 이름으로 명명된 이유는 속성과 행이 어떤 관계에 의해 모여진 집합이기 때문이라는 추측이 있다. 관계에 있는 속성의 개수를 차수(Degree), 행의 개수를 Cardinality라고 한다. 예를 들어 유저 테이블에 id, password, email, created_date 4개의 컬럼과 2만 개의 레코드가 존재한다면 차수가 4, cardinality는 20000이 되는 것이다.
 출처 : 위키피디아
출처 : 위키피디아관계형 데이터 모델에서 속성은 해당 속성이 가질 수 있는 모든 값에 대한 도메인을 가지며, 원자적이어야 한다. 원자적이라는 뜻은 더 이상 쪼개어질 수 없다는 뜻이다. 예를 들어 숫자 속성은 더 이상 쪼개질 수 없는 원자적인 속성이지만 집합이나 리스트와 같은 데이터 모음에 대한 속성과 여러 속성을 합친(Composite) 속성은 원자적이라고 볼 수 없다. 속성에는 null이라는 특별한 값이 허용된다. 그리고, 관계 간에는 순서가 없고, 행 간에도 순서가 없다(Unordered). 즉, 물리적으로 1000번째 레코드 다음에 1001번째 레코드가 존재하지 않을 수도 있다는 뜻이다.
RDB에서는 관계의 집합과 제약 조건의 집합으로 이루어져 있다. 제약 조건으로는 키 제약 조건(Key constraint), 개체 무결성 제약 조건(Entity integrity constraint), 참조 무결성 제약 조건(Referential integrity constraint) 등이 있다.
키는 슈퍼 키(Super key), 후보 키(Candidate key), 기본 키(Primary key)로 나뉜다. 슈퍼 키는 그 관계의 모든 행을 유일하게 식별할 수 있도록 하는 속성의 집합이다. 모든 속성을 모은 것을 슈퍼 키라고 할 수도 있지만, 가능하면 적은 개수의 속성으로 키를 구성하는 것이 행을 식별하는 데 이점이 있다. 그렇기 때문에 후보 키라는 개념이 있으며, 후보 키는 슈퍼 키 중 가장 속성의 개수가 적은 것이다. 예를 들어 슈퍼 키 A는 속성이 4개, 슈퍼 키 B는 속성이 2개, 슈퍼 키 C는 속성이 2개라면 B, C가 후보 키가 될 조건을 만족한다. 그중에서도 하나의 후보 키가 기본 키로 선택되고, 모든 관계는 단 하나의 기본 키만을 가진다.
참조 무결성 제약 조건은 RDB에서 매우 중요한 제약 조건 중 하나이다. 흔히 외래 키(Foreign key)로 알려진 키에 적용되는데, 외래 키의 대상 관계에 그 키를 가진 행이 반드시 존재해야 한다는 제약 조건이다. 이 무결성 제약 조건으로 관계있는 데이터가 반드시 DB에 존재한다는 보장을 할 수 있으므로 매우 유용하다.
관계 대수
관계형 데이터 모델에서 데이터 취급을 위한 연산 체계로 관계 대수(Relational algebra)가 사용된다. 관계 대수의 연산은 실제 SQL 언어에서의 연산과 대치되며, DBMS가 질의 처리를 하기 전 질의를 관계 대수로 먼저 인식한다. 관계 대수는 절차적 언어로 select, project, union, set difference, cartesian product, rename 6 가지 기본 연산으로 이루어져 있다. 이 연산들에 더해서 흔한 질의 표현의 단순화를 위해 대입, 교집합, 자연 조인, 세타 조인, 동등 조인, 외부 조인, 나누기 연산 등을 추가로 정의하여 사용한다. 단, 이러한 추가적인 연산은 연산 능력을 더 키우지는 않는다. 각 연산은 하나 혹은 두 관계를 입력으로 받아 새로운 관계를 결과로 낸다.
관계 대수에 대해서 이 글에서 설명하기는 힘들고(특히, 브런치에서는 수식 입력이 어렵다...), 링크해 둔 위키피디아 페이지가 잘 설명하고 있으니 참고하기 바란다.
SQL(Structured Query Language)
RDBMS를 통해 DB를 사용하기 위해 사용자는 SQL이라는 특수 목적의 프로그래밍 언어를 사용하여 DBMS에게 질의해야 한다. 앞서 관계 대수는 SQL의 연산으로 대치될 수 있다고 하였다. 관계 대수의 연산은 보통 "SELECT ~ FROM ~ WHERE" 식의 질의에 대치된다. 이는 데이터 조작 언어(Data Manipulation Language, DML)에 해당되는 기능이고, SQL은 크게 DML 외에도 데이터 정의 언어(Data Definition Language, DDL), 데이터 제어 언어(Data Control Language, DCL) 세 가지로 나뉜다.
데이터 정의 언어는 테이블이나 색인(Index), 제약 조건 등을 생성하거나 삭제, 수정하는 작업에 대한 언어이다. 앞서 RDB에서 관계는 테이블로 나타난다고 하였다. RDBMS는 테이블에서 데이터를 잘 찾기 위해 색인이라는 것을 만들고, 제약 조건들을 통해 데이터를 안정적으로 운영한다.
데이터 조작 언어는 DB에 대해 데이터 검색, 추가, 삭제, 갱신을 위한 언어이다. SELECT, INSERT, DELETE, UPDATE로 시작하는 SQL이 데이터 조작 언어에 포함된다.
데이터 제어 언어는 데이터에 대한 접근 권한을 제어하기 위한 언어이다. DBMS는 여러 유저에 의해 사용되는 소프트웨어이고, 보안 등의 목적을 위해 사용자에 따라 어떤 데이터에는 접근 가능하고, 어떤 데이터에는 접근 불가능하게 한다. 예를 들어, 애플리케이션에 대한 데이터만 관리하면 되는 사용자에게는 굳이 시스템에 대한 데이터에 접근할 수 없도록 하면 보안상으로 이점이 있을 것이다. 이는 최소 권한의 원칙(The principle of least privilege)과 리눅스의 다중 사용자 관점에서도 일맥상통하는 바가 있다.
DB를 다루기 위한 모든 작업에 SQL이 사용되기 때문에 당연히 사용자는 SQL을 잘 알아야 할 것이다. DBMS는 입력된 SQL을 최적화하기 위해 노력하지만 최적화에는 한계가 있기 때문에 어떤 SQL을 실행하느냐에 따라 질의 수행 속도가 천차만별로 차이나기도 한다. SQL에 대한 내용은 정말 방대하기 때문에 이 글에서 다루기 어렵다. 기본적인 SQL 학습에 대해서는 W3Schools의 튜토리얼을 추천한다. SQL에 대한 표준이 지정되어 있긴 하지만, 시스템에 따라서 세세한 부분의 차이가 있고, 또 제공하는 추가 기능들이 다르기 때문에 사용하려는 시스템의 매뉴얼을 잘 살펴봐야 할 것이다.
View
View는 테이블을 수정하지 않고 데이터를 보는 관점을 새롭게 정의하는 것으로, 논리적 테이블이라고 생각할 수 있다. 예를 들어, 사용자 테이블에 대해 특정 나이 이상의 사용자만을 보여주는 View를 정의하면 그러한 사용자들에 대한 데이터를 좀 더 편리하게 조회할 수 있을 것이다. DBMS는 여러 사용자가 함께 사용하기 때문에 실제 테이블이 어떻게 생겼는지는 숨기고 View만을 사용자에게 허용함으로써 보안을 추구할 수도 있다. 실질적으로 View는 다른 관점에서의 데이터를 보여주는 것일 뿐, 물리적으로 존재하는 테이블은 아님을 알아둬야 할 것이다.
반면, 실체화 뷰(Materialized View)는 자주 사용되는 View의 데이터를 따로 저장해둠으로써 질의 처리 속도를 향상할 수 있다. 즉, 실체화 뷰의 데이터는 물리적으로 존재한다. 말하자면 데이터를 캐시 해두는 것과 비슷하다.
무결성 제약 조건(Integrity Constraint)
무결성 제약 조건을 이용하면 DB 설계 단계에서 잘못된 데이터가 DB에 입력되고 유지되는 것을 막을 수 있다. 제약 조건은 SQL, 데이터 정의 언어에 의해 추가, 삭제, 수정된다. 널리 사용되는 무결성 제약 조건으로는 NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK가 있다. NOT NULL과 UNIQUE 제약 조건은 이름 그대로 어떤 값이 null이 아니어야 하는 제약 조건, 해당 관계 내에서 유일해야 한다는 제약 조건을 거는 것이다. PRIMARY KEY는 앞서 언급한 키 제약 조건에 해당되고, FOREIGN KEY는 외래 키로 참조 무결성 제약 조건을 만족시켜주기 위한 제약 조건이다. CHECK 제약 조건을 사용하면 어떤 데이터가 조건을 만족해야만 하도록 제한할 수 있다. (사실 NOT NULL 제약 조건은 CHECK 제약 조건의 하위 개념으로 볼 수 있다.)
외래 키에 대해서는 참조 조작이라 불리는 편의 기능이 제공되기도 한다. 자세한 내용은 외래 키의 링크된 위키피디아 문서를 참고.
Trigger
Tigger는 DB 관리의 편의를 위한 기능이다. 크게 Row level trigger, Statement level trigger로 나뉜다. Trigger의 선언과 삭제 또한 SQL로 이뤄진다. 예를 들어, 테이블에 새로운 데이터가 입력될 때 특정 컬럼의 값을 현재 시각으로 지정하거나, 행에 변화가 일어났을 때 어떤 작업을 수행해줘야 하는 상황 등에 유용하게 쓰일 수 있다. 좀 더 자세한 설명은 링크를 참고.
권한 관리
DBMS는 여러 사용자에 의해 이용되는 시스템이다. 그렇기 때문에 사용자별 권한을 관리할 수 있도록 기능을 제공해주는 것이 필요하다. 마치 리눅스에서 여러 사용자로 로그인하여 시스템을 이용할 수 있는 것과 비슷하다. 실제로 DBMS를 사용할 때는 사용자로서 로그인하여 질의를 실행할 수 있게 된다. 권한 관리에 의해서 시스템 관리자는 사용자마다 실행 가능한 질의를 제한할 수 있다. 관리할 수 있는 다양한 권한에 대해서는 다음 문서를 참고. 시스템마다 차이는 있지만 대체로 비슷하다.
개체-관계 모델(Entity-Relationship Model)
DB를 잘 설계하는 것은 매우 중요하다. 잘 설계된 DB는 관리되기 쉽고, 질의 수행 속도도 빨라질 수 있다. 서버의 병목 현상을 일으키는 요인이 대부분 DB 접근임을 생각하면 DB 설계를 잘 하는 것이 중요하다는 것을 더 느낄 수 있다.
관계형 데이터 모델을 사용하는 RDB에서는 데이터 구조화를 위해 개체-관계 모델로 모델링한다. 개체는 분리된 사물 하나하나에 대한 것으로, 관계는 두 개 이상의 개체들이 어떻게 서로 연관되어 있는지에 대한 정보이다. 개체-관계 모델링 산출물로 개체-관계 다이어그램이라는 그림을 만든다. 설계한 DB를 다이어그램으로 나타낸 것인데, 이 다이어그램을 그리는 방법도 여러 가지가 존재하며, 크게 전통적인 방법과 크로우즈 핏 방법으로 나뉜다. 또한, 개체-관계 다이어그램을 그리기 위한 툴들도 상용으로 많이 존재하며 쓰인다.
 출처 : 위키피디아
출처 : 위키피디아개체-관계 모델에서는 대개 각 개체를 위한 테이블과 관계를 위한 테이블들을 만드는 것으로 구현되며, 개체-관계 다이어그램이 만들어지면 설계 그대로 RDB로 옮길 수 있다. 관계에는 일대일 관계, 일대다 관계, 다대다 관계가 있다. 보통 일대일 관계는 개체에 대한 테이블에서 외래 키를 직접 두는 것으로, 일대다 관계와 다대다 관계는 관계를 위한 테이블을 별도로 선언하여 해당 테이블에서 개체 테이블에 대한 외래 키를 두는 것으로 구현된다.
개체-관계 모델링에 대한 자세한 자세한 내용은 링크해 둔 위키피디아 문서를 참고하길 바란다. 잘 모델링하기 위한 방법은 또 다른 방대한 분야이며, 다음에 설명할 내용인 정규화에서 일부 소개될 것이다.
정규화(Normalization)
RDB를 설계할 때 신경 쓰지 않으면 데이터의 중복이 많아진다. 정규화를 거치면 크고, 제대로 조직되지 않은 테이블들을 작게 나누면서(Decomposition) 데이터의 중복을 없애고 잘 조직된 구조로 만들어지게 된다. 그전에, 잘 조직되지 않은 테이블에서 일어날 수 있는 이상(Anomaly)들을 먼저 알아보기 위해 아래 테이블을 보자.
학번, 과목코드, 이름, 연락처
1601, C01, 강하늘, 010-1234-0000
1601, C02, 강하늘, 010-1234-0000
1602, A01, 서현진, 010-3210-9999
1603, B01, 최유정, 010-5555-1234
1603, C01, 최유정, 010-5555-1234
위 테이블에서는 대표적 이상인 삽입 이상(Insert Anomaly), 삭제 이상(Delete anomaly), 갱신 이상(Update Anomaly) 모두 나타난다. 삽입 이상은 관계에 데이터를 삽입할 때 의도와 상관없이 원하지 않는 값들도 함께 삽입하게 되는 현상이다. 위 테이블에서는 학생의 과목 정보 없이 연락처만을 추가하고 싶더라도 과목코드를 반드시 입력해야만 한다. 삭제 이상은 관계에 데이터를 삭제할 때 의도와 상관없는 값들도 함께 삭제되는, 연쇄 삭제가 일어나는 현상이다. 위 테이블에서는 학번 1602의 서현진 학생의 A01 과목을 취소하기 위해서는 해당 행을 삭제해야 하는데, 그럴 경우 연락처 정보까지도 잃게 된다. 갱신 이상은 관계의 행에 있는 속성 값을 갱신할 때 일부 행의 데이터만 갱신되어 데이터에 모순이 생기는 현상이다. 위 테이블에서는 최유정 학생이 연락처를 바꾸려 할 때 과목코드 B01, C01 모두에 대해 연락처가 수정되어야 하지만 실수로 하나의 행에서만 갱신이 일어날 수 있다. (예시 참고자료 : http://it-ing.tistory.com/50)
정규화를 거치면 위의 이상들이 일어나지 않도록 할 수 있다. 정규화는 단계적으로 적용되어 제 1 정규형(1NF), 제 2 정규형(2NF), 제 3 정규형(3NF), 보이스-코드 정규형(BCNF), 제 4 정규형(4NF), 제 5 정규형(5NF), 마지막으로 2002년에 소개된 제 6 정규형(6NF)을 만들게 된다. 정규화를 위해서는 먼저 함수 종속성을 알아야 한다. 여러 가지 법칙이 있지만, 정규화를 위해 알아둘 점은 어떤 속성에 의해 다른 속성의 값이 결정되는 속성이라는 것이다. 예를 들어, 직원 테이블이 직원 ID 속성과 직원 생일 속성을 가질 때 직원 생일 속성은 적원 ID 속성에 함수 종속(직원 ID → 직원 생일)이다. 후에 설명할 내용은 함수 종속성의 다른 속성들도 알아야 하므로 링크된 문서를 먼저 읽어보길 바란다.
현실적으로 과도한 정규화는 DB 질의 처리 속도를 떨어뜨리기 때문에 제 3 정규형 혹은 보이스-코드 정규형까지만 정규화를 진행한다. 제 3 정규형만 해도 많은 조인 연산을 요구하게 되기 때문에 제 2 정규형으로 비 정규화시키기도 한다. 따라서, 이 글에서는 제 4 정규형 일부까지만 다루고 넘어간다.
제 1 정규형
제 1 정규형은 테이블의 각 속성이 원자적이어야 한다. 이는 요즘 쓰이는 RDBMS에서 테이블을 만들 때 각 컬럼이 원자적인 속성일 것을 강제하기 때문에 지켜지지 않는 경우는 거의 없다. 또한, 기본 키로 각 행을 식별할 수 있어야 한다. 마지막으로 제 1 정규형을 만족하기 위해서는 중복되는 항목이 없어야 한다는 조건이 있다. 위키피디아 페이지에서도 설명하듯이 이 정의는 조금 모호하다. 크게 행을 가로지르며 중복되는 항목과 행 내에서의 중복되는 항목이 없도록 해야 한다는 조건이 있다.
왼쪽이 행을 가로지르며 중복되는 항목, 오른쪽이 행 내에서의 중복되는 항목에 대한 예시 테이블이다. 딱 봐도 행을 가로지르며 중복되는 항목은 전화번호를 여러 개 두기 어렵다는 것뿐만 아니라 질의를 어렵게 하고, 행 내에서의 중복되는 항목은 속성의 의미가 모호해진다. 제 1 정규형을 만족하기 위해서는 테이블을 분해하여 다음과 같이 만들어야 한다.
 출처 : 위키피디아
출처 : 위키피디아이 디자인에서는 전화번호들의 중복되는 항목이 나타나지 않는다. 실제로 질의하여 전화번호를 함께 조회할 때는 조인 연산을 이용한다.
제 2 정규형
제 2 정규형을 만족하기 위해서는 후보 키 전체로 후보 키에 속하지 않는 속성을 결정할 수 있어야 한다. 따라서, 하나의 속성으로만 후보 키로 사용할 경우 제 2 정규형을 만족한다. 이 조건만 두고 봤을 때는 직관적이지 않지만, 아래 예를 들어 제 2 정규형을 만족시키면서 갱신 이상을 없애는 것을 보이겠다.
 출처 : 위키피디아
출처 : 위키피디아위 테이블은 종업원과 기술 두 속성을 모두 사용해야 후보 키로 쓸 수 있다. 즉, 후보 키는 {종업원, 기술}이다. 그러나 근무지 속성은 종업원 속성에만 종속되어 있으며, 근무지 속성은 중복된다. 이 테이블에서는 Jones의 근무지를 갱신할 때 Typing, Shorthand에 대한 근무지만 갱신될 수 있는 위험이 있다.
 출처 : 위키피디아
출처 : 위키피디아제 2 정규형을 만족시키기 위해 기존의 테이블을 분해한 예이다. 이 구조에서는 갱신 이상이 발생하지 않는다. 그러나 제 2 정규형을 만족시키는 모든 테이블이 갱신 이상이 없는 것은 아니다. 아래 예는 제 2 정규형을 만족하지만 갱신 이상이 발생한다.
 출처 : 위키피디아
출처 : 위키피디아{대회, 연도}로 우승자 속성과 우승자 생년 월일 속성이 결정되지만 우승자 생년 월일은 중복된 데이터가 존재할 수 있으므로 갱신 이상이 발생할 위험을 갖고 있다. 이 문제의 원인은 우승자 생년월일 속성이 가지는 추이 종속성이다. 우승자 생년월일 속성은 우승자 속성에 의해서 결정되는데, 우승자 속성은 키 {대회, 연도}에 의해서 결정되기 때문이다. 제 3 정규형을 만족시키면서 이 문제가 사라질 수 있다.
제 3 정규형
제 3 정규형을 만족하기 위해서는 당연히 제 2 정규형을 만족하면서 동시에 모든 속성이 기본 키에 대해서만 의존되어야 한다. 이 조건은 자연히 추이 종속성이 발생하지 않을 것을 요구한다. 각 속성이 기본 키에 의해서만 결정되어야 하기 때문이다.
 출처 : 위키피디아
출처 : 위키피디아 출처 : 위키피디아
출처 : 위키피디아각 테이블은 기본 키에 의해서만 모든 속성이 결정된다. 대회 우승자 테이블은 {대회, 연도}가 기본 키이고, 우승자 생년 월일 테이블은 {우승자}가 기본 키이다. 제 3 정규형에서는 갱신 이상이 덜 발생한다.
보이스-코드 정규형과 제 4 정규형
보이스-코드 정규형은 강한 제 3 정규형이라고도 불린다. 제 3 정규형은 갱신 이상이 덜 일어나게 하지만, 완전히 갱신 이상이 일어나지 않게 하는 것은 아니다. 사실 보이스-코드 정규형도 이상이 존재하지 않도록 하는 정규형은 아니다. 이상이 존재하지 않는 정규형은 도메인-키 정규형으로 알려져 있으나, 도메인-키 정규형을 만드는 구체적인 방법이 밝혀지지 않았다.
보이스-코드 정규형을 만족하기 위해서는 모든 결정자가 후보 키여야 한다. 후보 키는 모든 행을 식별할 수 있는 최소의 속성 집합이라는 점을 상기하자. 좀 더 자세한 분석은 링크된 문서를 참고하길 바란다.
제 4 정규형은 다치 종속성이 없을 것을 요구한다. 다치 종속성이 있을 경우 데이터는 중복되기 때문에 이를 없애고자 하는 것이다. 그러나 앞서 언급한 바와 같이 현실적으로 제 4 정규형 이상까지 정규화하는 일은 잘 일어나지 않는다. 언제나 그렇듯이 개발이라는 일은 여러 가지를 복합적으로 고려해야 하는 일이고, 정규화 외에도 관심을 둬야 할 일들이 많기 때문에 우선순위가 밀린다. 현실적으로 제 3 정규형 정도까지만 만족해도 큰 이상 없이 DB를 운영할 수 있으며, 성능 등의 문제에 의해 오히려 비정규화 작업을 거친다. 다만, 다치 종속성에 의해 데이터 중복이 일어날 수 있다는 것을 인지하고 있는 것이 도움은 될 것이라 생각한다.
데이터베이스 사용 관점 정리
지금까지 관계형 데이터베이스를 사용하는 측면에서 알아야 할 것들에 대해 살펴보았다. DB는 3단계 스키마로 계층적 분리를 통해 관리의 효율성을 도모한다. DB는 관리 시스템인 DBMS에 의해 관리된다. 사용자는 DBMS를 거쳐 DB를 사용하며, DBMS는 여러 사용자들이 함께 사용하는 시스템이다.
관계형 데이터 모델은 DB에서 데이터를 나타내기 위해 많이 사용되는 모델로, 관계형 데이터 모델을 사용하는 DB를 관계형 데이터베이스라고 한다. RDB는 관계와 제약 조건의 집합이다. 관계에 대한 연산을 관계 대수라는 연산 체계로 다룬다.
사용자는 DBMS를 이용하기 위해 SQL이라는 언어를 사용하여 질의한다. SQL은 데이터 정의 언어, 데이터 조작 언어, 데이터 제어 언어로 나뉘며, 데이터 조작 언어 부분은 관계 대수와 대치된다. 또한, DBMS는 사용자가 좀 더 편리하게 DB를 사용할 수 있도록 View, 무결성 제약 조건, Trigger, 권한 관리 등의 기능을 제공한다.
관계형 데이터 모델로 현실 세상의 문제를 모델링하기 위해 개체-관계 모델링 방법을 많이 쓴다. 개체-관계 모델링 작업 후에는 개체-관계 다이어그램이 만들어지고, 이 다이어그램 그대로 RDB에 구현될 수 있다. DB에 중복된 데이터가 많다면 잘 관리되기 어렵다. 중복된 데이터가 없고 관계들이 잘 나뉠 수 있도록 하기 위해 정규화 작업을 거친다. 현실적으로 제 3 정규형 또는 보이스-코드 정규형을 만족하는 수준까지만 정규화하며, 필요에 따라 비정규화 작업을 하기도 한다.
데이터베이스 개발 관점 개요
지금부터는 데이터베이스를 만들기 위해서 고려해야 할 점들에 대해 알아본다. 데이터베이스에서 주요 주제를 살펴보면 트랜잭션 관리 및 동시성 제어, 복구, 저장 장치, 색인, 질의 처리가 있다. 트랜잭션은 DB 사용에 있어 중요한 4가지 요구사항을 만족시켜주는 기능이고, DBMS는 여러 사용자에 의해 이용되므로 트랜잭션들을 동시에 잘 실행하기 위한 고민이 필요하다. 시스템은 언제든지 잘못될 수 있고, 심지어 트랜잭션 실행 도중 문제가 발생할 수도 있다. 에러가 아예 발생하지 않도록 하는 것은 불가능하기 때문에 에러가 발생했을 때 잘 복구할 수 있도록 하는 것이 중요하다.
데이터는 저장 장치에 기록된다. 항상 저장 장치에 접근하는 것이 성능 저하의 가장 큰 요인이기 때문에 어떻게든 저장 장치를 최대한 잘 이용할 수 있기 위한 고민이 필요하다. 또한, 방대한 데이터를 저장하여 사용하기 때문에 데이터를 잘 찾을 수 있도록 도와주는 색인이 꼭 필요하다. 널리 쓰이는 3가지 색인 구현에 대해 알아볼 것이다. 마지막으로 DBMS에서 질의 처리를 위해 거치는 과정에 대해 알아보면서 실제로 질의가 어떻게 실행되는지에 알아볼 것이다.
트랜잭션(Transaction)
상용 DB 시스템들은 대부분 트랜잭션 기능을 제공한다. 트랜잭션이 무엇인지 설명하는 여러 가지 방법이 있겠지만, 트랜잭션은 하나의 논리적 작업이라고 볼 수 있다. 예를 들어, 은행 시스템에서 송금이라는 작업을 한다면 최소한 한 사람의 예금을 감소시키고 다른 한 사람의 예금을 증가시켜야 할 것이다. 만약 송금자의 예금을 감소시키기만 하고 시스템에 문제가 발생하여 상대방의 예금이 증가하지 않는다면 큰 문제가 발생할 것이 자명하다. 그렇기 때문에 실제로는 여러 연산으로 이루어진 작업이지만, 사용자들은 이것을 하나의 작업으로 보고 싶어 한다. 또한, DBMS는 여러 사용자에 의해 사용되는 시스템이기 때문에 여러 사용자들의 트랜잭션을 동시에 수행해야 성능 문제가 발생하지 않을 것이다. 그러나 여러 트랜잭션이 동시에 실행되는 것은 운영 체제의 임계 영역처럼 문제가 발생할 여지를 만들게 된다. 따라서, 트랜잭션에 대해 주요 이슈는 크게 트랜잭션 실행 중 장애가 일어나는 것에 대한 이슈와 여러 트랜잭션을 동시 실행에 대한 이슈 두 가지로 나뉜다.
SQL로 작성되는 트랜잭션은 매우 복잡하기 때문에 앞으로 트랜잭션 내의 연산을 읽기, 쓰기로만 단순화한 모델로 설명한다. 실제로 모든 연산은 읽기, 쓰기로만 이루어지므로 계산 능력에 있어서 차이는 없다.
트랜잭션의 성질과 상태
트랜잭션은 DB의 무결성을 지키기 위해 ACID 성질을 가져야 한다. 각 성질의 앞 글자를 딴 것으로 자세한 성질은 다음과 같다.
원자성(Atomicity) : 트랜잭션 내의 모든 연산이 적용되거나, 아무것도 적용되지 않아야 한다.
일치성(Consistency) : 트랜잭션 수행 전 DB가 무결한 상태였다면 트랜잭션 수행 후에도 DB는 무결한 상태여야 한다.
고립성(Isolation) : 여러 트랜잭션이 동시에 실행되고 있어도 사용자는 자신의 트랜잭션만 실행되고 있다고 느껴야 한다.
지속성(Durability) : 완료된 트랜잭션의 결과는 시스템 장애가 발생하더라도 DB에 반영되어야 한다.
송금을 예로 들어 다시 생각해보자. 한 사람의 예금을 감소시키고 다른 사람의 예금을 증가시키는 논리적 작업은 모두 적용이 되거나, 아니면 아예 하나도 적용되지 않아야 한다. 정상적으로 모든 작업이 적용됐다면 문제가 없는 것이고, 만약 아무 연산도 적용되지 않았다면 다시 트랜잭션을 실행하면 될 것이다. 트랜잭션 내에서는 연산 도중 DB의 무결성이 깨지는 상황이 올 수 있다. 하지만 당연히 연산이 끝난 뒤에는 DB의 무결성 제약들을 모두 만족해야만 할 것이다. 은행 시스템은 여러 사용자들의 요청을 처리해야 한다. 여러 트랜잭션이 동시에 실행될 것이지만, 각 트랜잭션 간의 영향은 없어야 한다. 더불어 앞서 트랜잭션 실행 도중에는 무결성을 만족하지 않는 상태가 될 수 있다고 하였다. 이 상황에서 고립성을 지키지 않고 무결성이 깨진 상태의 값을 이용한 계산은 잘못된 계산 결과를 초래하게 될 것이다. 마지막으로 당연히 성공적으로 완료된 트랜잭션은 후에 에러가 발생하여도 문제가 없어야 한다. 만약 송금을 한 다음 날 시스템 장애로 인해 송금 사실을 고객에게 확인해줄 수 없다면 큰 문제가 발생할 것이다.
트랜잭션의 상태는 수행 중(Active), 부분 완료(Partially committed), 완료(Committed), 실패(Failed), 철회(Aborted) 상태로 나뉜다. 정상적으로 수행 중인 트랜잭션이 모든 문장을 실행하고 나면 부분 완료 상태가 되며, 안전한 저장 장치에 로그 쓰기 작업 등이 끝나고 나면 완료 상태가 된다. 그러나 도중 트랜잭션 실행 도중 문제가 발생한다면 실패 상태가 되고, 복구해야 할 것들을 복구한 뒤 철회 상태가 된다. 또는, 트랜잭션 실행 도중 사용자 요청에 의해 실행 취소가 되기도 한다.
 출처 : https://www.tutorialspoint.com/dbms/dbms_transaction.htm
출처 : https://www.tutorialspoint.com/dbms/dbms_transaction.htm
직렬 가능성(Serializability)
컴퓨터 자원을 효율적으로 사용하기 위해 트랜잭션들을 동시 실행하고 싶다. 이는 운영체제의 멀티프로그래밍과 비슷하다. 그러나 DB에서는 올바른 트랜잭션 동시 실행이 무엇인가에 대해 결정해야 한다. 다른 트랜잭션의 연산과 혼합되어 동일한 DB에 작업할 것이기 때문이다. 당연히 트랜잭션 하나하나를 순서대로 실행하는 것은 문제를 일으키지 않는 올바른 순서지만 이는 동시 실행이라 보기 어렵다. 여러 트랜잭션을 동시에 잘 실행하기 위한 것을 동시성 제어라고 한다.
트랜잭션을 올바르지 않게 실행할 경우 발생하는 문제는 Dirty read, Lost update, Unrepeatable read 세 가지가 있다. Dirty read는 아직 완료되지 않은 값을 읽는 문제, Lost update는 어떤 트랜잭션에서 수정한 값을 다른 트랜잭션에서 수정해버리면서 이전의 갱신을 잃게 되는 문제이다. Unrepeatable read는 한 트랜잭션이 처음 읽은 값과 나중에 다시 읽었을 때의 값이 달라지는 문제로 트랜잭션 입장에서는 어떤 값을 읽을 때마다 다른 값을 읽을 수도 있게 되는 문제이다. 앞으로 고민하고자 하는 동시성 제어는 위 세 가지 문제를 방지하는 방법이다.
우리의 모델에서는 트랜잭션 내에 읽기, 쓰기 연산 여러 개가 나열되어 있다. 각 트랜잭션의 연산들을 순서대로 실행한 것을 스케쥴(Schedule)이라고 하자. 각 트랜잭션을 순서대로 실행한 것을 직렬 스케쥴(Serial schedule)이라고 한다. 당연히 매우 많은 스케쥴이 만들어질 수 있으나, 앞서 언급한 세 가지 문제가 없는 스케쥴을 찾는 것이 우리의 목표이며, 직렬 스케쥴과 실행 결과가 동일한 스케쥴은 문제가 없는 스케쥴로 직렬 가능 스케쥴(Serializable schedule)이라고 한다. 직렬 가능 스케쥴은 직렬 스케쥴 중 단 하나와만이라도 동일한 결과를 보이면 된다.
물론 다양한 직렬 가능 스케쥴이 존재하겠지만 직렬 가능 스케쥴을 빨리 찾을 수 있어야 할 것이다. 직렬 스케쥴과 동일함을 정의하는 방식으로 충돌 직렬 가능성과 뷰 직렬 가능성이 있다.
충돌 직렬 가능성(Conflict serializability)
충돌(Conflict)이 무엇인지 먼저 알아보자. 동일한 데이터에 대해 두 연산이 이뤄질 때, 최소 하나의 연산이 쓰기 연산이면 두 연산은 충돌한다고 한다. 동일한 데이터가 아니면 충돌이 아니고, 두 연산이 모두 읽기 연산이어도 충돌이 아니다. 운영 체제에서의 경쟁 조건을 생각해보면 쉬울 것이다.
비 충돌 연산은 서로 순서를 바꾸어도 실행 결과에 차이가 없지만 충돌 연산은 순서에 따라 실행 결과가 달라지기 때문에 스케쥴을 결정하기 위해 고려해야 할 대상이 된다. 스케쥴에서 비 충돌 연산의 순서를 바꾸어 직렬 스케쥴이 되면 충돌 직렬 가능 스케쥴(Conflict serializable schedule)이라고 한다. 충돌 직렬 가능 스케쥴에 대한 더 자세한 설명은 다음 링크를 참고.
뷰 직렬 가능성(View serializability)
같은 트랜잭션들로 이루어진 스케쥴 S1과 S2에 대해
S1의 트랜잭션 Ti에서 처음 읽은 데이터 Q값과 S2의 Ti가 Q에 대해 같은 값을 읽고
S1의 Ti가 쓰기 한 값을 다른 트랜잭션 Tj가 읽는다면 S2에서도 마찬가지로 Ti가 수정한 값을 Tj가 읽고
S1의 마지막 쓰기 연산이 S2의 마지막 쓰기 연산과 동일하다면
이 스케쥴을 뷰 동치(View equivalence)라고 한다. 만약 직렬 스케쥴과 뷰 동치인 스케쥴이라면 그 스케쥴을 뷰 직렬 가능 스케쥴(View serializable schedule)이라고 할 수 있다. 뷰 동치 정의가 매우 복잡하다. 좀 더 자세한 내용은 다음 링크를 참고.
충돌 직렬 가능 스케쥴은 뷰 직렬 가능 스케쥴의 부분 집합이고, 뷰 직렬 가능 스케쥴은 보다 많은 스케쥴들을 포함한다.
직렬 가능한 스케쥴 선택
뷰 직렬 가능 스케쥴 외에도 더 많은 스케쥴들이 직렬 가능할 수 있다. 그러나 사용자가 모든 질의에 대해 미리 다 요청을 보내 놓는 게 아니기 때문에 모든 연산의 순서를 알지 못할뿐더러, 다른 직렬 가능한 스케쥴을 찾는 것은 복잡한 계산을 필요로 한다. 심지어 뷰 직렬 가능 스케쥴조차도 뷰 직렬 가능 스케쥴인지 검증하는 문제는 NP-완전 수준의 문제다. 그렇기 때문에 현실적으로는 충돌 직렬 가능성에 대해서만 고려하여 직렬 가능한 스케쥴을 찾는다고 생각하면 된다.
충돌 직렬 가능성을 판별하기 위해서는 스케쥴의 연산에 따른 선행 그래프(Precedence graph)를 사용하면 된다. 그래프에서 노드는 트랜잭션을, 충돌하는 데이터가 존재하는 노드 간에 엣지를 두면 선행 그래프가 만들어진다. 이 선행 그래프에서 회로(cycle)가 존재하면 충돌 직렬 가능하지 않은 스케쥴이다.
뷰 직렬 가능 스케쥴에 대해 쉬운 검증 방법이 하나 있다. 충돌 직렬 가능 스케쥴에 대해 Blind write(읽지 않고 쓰는 작업)의 존재 여부를 활용하는 것이다. 그러나 이것뿐이다.
다양한 스케쥴
지금까지는 모든 트랜잭션이 실행이 정상적으로 되었을 때에 대해서만 고려한 스케쥴이었다. 그러나 DB에서는 항상 장애에 대한 고려가 필요하다. 회복 가능 스케쥴은 어떤 데이터 Q에 대해 쓰기 작업을 한 트랜잭션 Ti와 Ti가 쓰기 연산한 후에 Q를 읽는 트랜잭션 Tj가 있을 경우 Ti가 먼저 완료된 후에야 Tj가 완료되어야 하는 스케쥴이다. 이 조건이 필요한 이유는 Ti가 실행 도중 철회될 수 있기 때문이다. 이 경우 철회된 값을 읽었던 트랜잭션의 연산을 복구할 수 없는 문제가 발생한다. 이러한 문제가 일어나지 않고, 복구 가능하도록 실행하는 스케쥴을 회복 가능 스케쥴(Recoverable schedule)이라고 한다.
동일한 데이터에 접근했던 트랜잭션이 철회됨에 따라 다른 트랜잭션도 철회되는 현상을 연쇄 철회(Cascading rollbacks)이라고 한다. 힘들게 다 실행해놨더니 다시 복구해야 하는 상황이 되는 것이므로 가능하면 연쇄 철회가 일어나지 않기 위해 노력해야 한다. 연쇄 철회가 필요 없는 스케쥴(Avoids cascading aborts schedule)은 완료된(Committed) 데이터만을 읽도록 허용한다. 즉, 어떤 데이터에 대해 다른 트랜잭션이 먼저 쓰기 연산을 했다면 그 트랜잭션이 먼저 완료되기를 요구한다.
제한적인 스케쥴(Strict schedule)은 어떤 데이터에 대해 쓰기 연산을 한 트랜잭션이 완료되거나 철회되기 전에는 다른 스케쥴이 읽기 연산도, 쓰기 연산도 할 수 없게 하는 스케쥴이다. 즉, 연쇄 철회가 필요 없는 스케쥴보다 더 적은 범주의 스케쥴만을 포함한다. 아래 그림은 각 스케쥴 범주를 보여준다.
 출처 : https://en.wikipedia.org/wiki/Schedule_(computer_science)
출처 : https://en.wikipedia.org/wiki/Schedule_(computer_science)
동시성 제어
지금까지 다양한 스케쥴에 대해 알아보았다. 우리가 원하는 스케쥴은 직렬 가능 스케쥴이면서 회복 가능 또는 연쇄 철회를 방지하는 스케쥴이다. 앞서 언급하였지만 트랜잭션 전체의 연산을 미리 알지 못하기 때문에 이미 트랜잭션을 실행한 뒤에야 어떤 스케쥴인지 판별 가능하다. 그렇기 때문에 어떠한 규약을 통해 실행하면 원하는 스케쥴대로 실행되게 하는 규약을 찾고 싶다. 이러한 규약을 동시성 제어 규약(Concurrency control protocol)이라고 한다.
지금까지 개발된 동시성 제어 규약으로는 Locking, Timestamp ordering, Multiversion, Optimistic protocol이 있다. 상용 시스템에서는 Locking 규약이 주로 쓰인다. 다음 항목부터 각 동시성 제어 규약에 대해 더 자세히 알아보겠다.
Lock-based Protocol
락(Lock) 모드로는 Shared-lock과 eXclusive-lock 두 가지 모드가 있다. 각 모드를 S 모드, X 모드라고 부르며, S 모드는 읽기 연산을 할 때, X 모드는 쓰기 연산을 할 때 사용한다. 충돌 연산에서도 그랬듯이 S 모드는 서로 호환되지만 X 모드는 호환되지 않는다.
Lock-based protocol에서 트랜잭션은 모든 읽기/쓰기 연산을 하기 전에 락을 먼저 획득해야 한다. 호환 불가능한 락을 얻으려 할 때는 이전의 락이 풀릴 때까지 기다렸다가 락을 받은 뒤에야 연산을 수행할 수 있다. 마치 세마포어와 비슷하다. X 모드 락은 다른 모드들과 호환되지 않으므로 단 하나의 트랜잭션만이 가질 수 있음을 알 수 있다.
두 단계 락킹 규약(Two-phase Locking Protocol)
기본적인 락 규칙 외에도 직렬 가능 스케쥴을 만들기 위한 추가적인 규칙이 필요하다. 두 단계 락킹 규약은 직렬 가능 스케쥴을 만들기 위한 규약 중 하나이다. 두 단계 락킹 규약에서는 확장 단계(Growing phase)와 수축 단계(Shrinking phase)로 단계를 나누어 확장 단계에서만 락을 추가로 할당받을 수 있고, 락을 풀기 시작하면 수축 단계가 되면 추가적인 락을 얻을 수 없게 한다.
 출처 : http://opensource.telkomspeedy.com/repo/abba/v06/Kuliah/SistemOperasi/BUKU/img/index.html
출처 : http://opensource.telkomspeedy.com/repo/abba/v06/Kuliah/SistemOperasi/BUKU/img/index.html두 단계 락킹 규약의 변형으로 엄격(Strict) 두 단계 락킹 규약과 엄중(Rigorous) 두 단계 락킹 규약이 있다. 엄격 두 단계 락킹 규약은 트랜잭션이 종료될 때까지 쓰기 락을 계속 가져가고 읽기 락은 중간에 해제 가능하도록 하는 규약이다. 엄격 두 단계 락킹 규약을 준수하면 연쇄 철회가 일어나지 않게 된다. 트랜잭션이 완료된 뒤에야 쓰기 연산이 일어난 데이터에 다른 트랜잭션이 접근하지 못하게 하기 때문이다. 엄중 두 단계 락킹 규약은 읽기 락도 트랜잭션 종료 시까지 유지함으로써 트랜잭션 완료 순서대로 직렬 된다. 두 단계 락킹 규약이 모든 충돌 직렬 가능 스케쥴을 만드는 것은 아니고, 충돌 직렬 가능 스케쥴 중 일부 스케쥴로 실행되게 하는 것뿐이다.
읽기 락을 걸었던 데이터에 대해 쓰기 락을 걸게 될 수도, 쓰기 락을 걸었던 데이터에 대해 읽기 락으로 바꾸려 할 수도 있다. 이러한 변환을 락 변환(Lock conversion)이라고 한다. 락 변환을 고려하여 확장 단계에서는 S 모드 락, X 모드 락을 얻거나 S 모드 락을 X 모드 락으로 변환(upgrade)하는 것만을 허용하며, 수축 단계에서는 S 모드 락, X 모드 락을 풀거나 X 모드 락을 S 모드 락으로 변환(downgrade)하는 것만을 허용한다.
두 단계 락킹 규약이 항상 충돌 직렬 가능한 스케쥴을 생성하는 것에 대한 증명은 선행 그래프를 활용하여 가능하다. 선행 그래프 상에서 선행 노드는 수축 단계에 들어갔음을 의미하며 회로가 존재하기 위해서는 수축 단계에 들어갔던 노드가 다시 확장 단계가 되어야 한다는 것을 뜻하므로 모순이 발생하는 것이 증명 아이디어이다.
락 관리
시스템은 연산에 대해 자동적으로 락을 획득, 해제하도록 할 수 있기 때문에 사용자는 락을 획득하고 해제하는 것에 대해 신경 쓰지 않아도 된다. 시스템은 락을 관리하기 위해 프로세스를 독립적으로 구성할 수도 있다. 락을 관리하는 락 매니저(Lock manager)는 락 테이블(Lock table)을 관리하며, 락 관리는 빠른 시간 안에 수행되어야 하므로 메모리에서 관리한다.
락을 사용하면서 데드락(Deadlock) 발생 위험이 당연히 존재한다. 데드락에 대한 처리를 하지 않으면 시스템이 멈춰버릴 것이다. 이에 대한 적절한 처리 방법이 필요한데, 나중의 항목에서 몇 가지 방법을 소개할 것이다. 락 충돌이 일어나는 경우 트랜잭션은 락을 획득하기 위해 대기 상태로 기다린다. 그러나 락 배분 정책이 잘못되면 무한정 기다리는 기아 상태(Starvation)가 발생할 수도 있다. 당연히 기아 상태가 발생하지 않도록 잘 설계 및 구현해야 한다.
그래프 기반 규약(Graph-based Protocol)
만약 데이터에 부분 순서(Partial order)가 존재한다면 그래프 기반 규약을 사용할 수도 있다. 다음 링크는 그래프 기반 규약을 설명하는 유튜브 강의이다. 일반적인 데이터라면 부분 순서가 존재하지 않겠지만 DB에서 반드시 운영하는 데이터 중 순서가 반드시 존재하는 데이터가 있다. 바로 색인이다. 그래프 기반 규약 중 가장 간단한 형태인 트리 기반 규약을 알아보자.
 출처 : https://sites.google.com/site/projectcodebank/
출처 : https://sites.google.com/site/projectcodebank/트리 기반 규약에서는 락을 언제든지 획득하고 해제할 수 있다. 다만 한 번 락을 획득한 항목에 대해서는 다시 락을 획득할 수 없다. 두 단계 락킹 규약과 가장 큰 차이가 락 해제 후에 다시 획득이 가능하다는 것이다. 또한, 한 방향으로만 락이 흘러가기 때문에 데드락이 발생하지 않는다. 그러나 규약상의 이유로 굳이 락을 필요로 하지 않는 데이터에 대해서도 락을 획득해야 한다는 것이 단점이다. 또한, 회복이 불가능한 스케쥴과 연쇄 철회 스케쥴을 생성하기도 한다.
다중 단위 크기 락킹(Multiple Granularity Locking)
락킹 자체에 대해 더 생각해보자. 지금까지는 어떤 데이터 항목에 대해 락을 획득한다고 하였다. 그렇다면 어떤 데이터에 락을 걸 수 있을까? 상용 시스템들은 여러 크기의 락을 지원하며 이를 다중 다중 단위 크기 락킹(MGL)이라고 한다. DB는 계층적으로 DB, 관계(Relation), 페이지(Page), 레코드(Record)로 나뉜다. DB는 여러 관계들의 집합이며, 관계는 여러 페이지의 집합, 그리고 페이지 안에는 여러 개의 레코드들이 존재한다. 상위 계층 노드에 대해 명시적으로 락을 획득할 경우 하위 노드에 대해서 묵시적으로 락을 획득하는 효과가 있다.
또한, 락 모드를 더 세분화함으로써 동시성 향상을 도모한다. 다중 단위 크기 락킹에 대한 더 자세한 설명은 다음 링크의 유튜브 강의를 참고하기 바란다.
데드락 처리
락 기반 규약에서 데드락은 어쩔 수 없이 발생하며, 처리를 해줘야 한다. 타임 아웃, 방지, 감지 및 해결 세 가지 방식이 있다. 타임 아웃 방식은 일정 시간 이상 락을 위해 대기하지 않게 하고, 방지 방식은 두 단계 락킹 규약이 아닌 그래프 기반 락킹 규약을 사용하게 하는 방식이다. 방지 방식에는 트랜잭션에서 요구하게 될 모든 락을 미리 획득하는 방법도 포함되는데, 실제로는 트랜잭션에서 접근하게 될 데이터를 미리 알 수 없으므로 실효성이 없다.
또 다른 대표적인 데드락 방지 방식은 Wait-die 방식과 Wound-wait 방식이 있다. Wait-die 방식은 락 충돌 발생 시 늙은 트랜잭션(시작한 지 오래된)일 경우 기다리고, 어린 트랜잭션(시작한 지 덜 오래된)일 경우 스스로를 철회하는 방식이다. 그리고, Wound-wait 방식은 늙은 트랜잭션이 젊은 트랜잭션이 가지고 있던 락을 필요로 할 경우 젊은 트랜잭션을 철회시켜버린 뒤 락을 가져가고, 젊은 트랜잭션이 늙은 트랜잭션의 락을 필요로 할 경우 기다리는 방식이다. 두 방식 모두 오래된 트랜잭션이 유리한 방식이므로, 기아 상태가 발생하지 않기 위해서는 철회되기 전 처음 시작할 때의 타임스탬프를 기반으로 얼마나 오래된 트랜잭션인지 판단해야 한다. 오래된 트랜잭션을 우선하는 이유는 이미 많은 작업을 수행하였기 때문에 철회하는 비용이 더 클 가능성이 높기 때문이다.
데드락 감지 방식으로는 방향성을 가지는 대기 그래프를 이용한 방법이 있다. 그래프에 회로가 존재하면 데드락이 발생한 것인데, 간단한 알고리즘으로 회로가 존재하는지 알 수 있다. 감지는 쉽지만 해결은 쉽지 않다. 상용 시스템에서는 데드락을 일으킨 트랜잭션인 Current blocker를 철회시키는 방법을 많이 쓴다. Current blocker는 대기 그래프에서 회로를 만든 노드이다. 철회 비용이 저렴한 트랜잭션을 철회하면 더 좋겠지만, 그 계산이 어렵기 때문이다.
락 대기 조차도 간혹 일어나는데, 데드락은 더더욱 간혹 일어난다. 상용 시스템에서는 다양한 요구사항들이 존재하고, 데드락은 시스템에 있어서 치명적인 부분이 아니기 때문에 앞서 언급한 방법들이 빈틈이 많아 보여도 큰 문제가 되지 않는다.
팬텀 현상(Phantom Problem)
관계에 새로운 행을 추가하거나 삭제하는 경우 팬텀 현상이 일어난다. 행 삽입 및 삭제 시 행 수준의 락을 지원하는 시스템에서 팬텀 현상이 일어날 수 있다. 어떤 관계에 대한 집계 연산을 수행하는 트랜잭션은 읽기 락을 사용할 텐데, 새로운 행을 추가하려는 트랜잭션은 쓰기 락을 사용하면서 서로 호환되지 않기 때문에 집계 연산을 하는 트랜잭션이 새로 추가된 행을 인식하지 못하게 된다. 이는 행을 삭제할 때도 비슷하다.
행을 추가하거나 삭제할 때마다 테이블 수준의 락을 사용하는 것은 성능상에 치명적이므로 피해야 한다. 팬텀 현상을 피하기 위해서는 색인에 대해 락을 거는 방식이 널리 쓰인다. 색인에 대해 크래빙(Crabbing) 방식으로 락을 사용한다. 크래빙 방식은 트리 기반 규약으로 락을 사용하는 것인데, 부모 노드에 대해 먼저 락을 건 뒤, 자식 노드에 대해 락을 잡고 부모 노드에 걸었던 락을 해제하는 방식이다. 그러다 행을 추가 혹은 삭제함에 따라 부모 노드에 변화가 생기면 부모 노드에 대해 다시 락을 획득하려고 한다. 당연히 데드락이 발생할 수 있는 방법이므로 데드락 처리가 필요하다. 크래빙 방식 외에는 Predicate locking, Next-key locking 등의 방식이 제안되어 있다.
트랜잭션 고립성 제어
어떤 응용 프로그램은 트랜잭션이 완벽한 일치성을 요구하지 않을 수도 있다. 일치성의 수준이 조금 떨어지더라도 시스템의 성능이 더 향상되는 것을 원할 수 있기 때문이다. 일치성 수준을 완화(Weak levels of Consistency) 하기 위해 보편적으로 지원되는 형식이 두 단계 일치성이다. 읽기 락을 제한 없이 획득 및 해제할 수 있기 때문에 직렬 가능 스케쥴임이 보장되지 않지만 성능을 향상할 수 있다.
두 단계 일치성 중에서 커서 안정 방식(Cursor stability)은 데이터 읽기를 위한 커서가 위치하는 동안에만 읽기 락을 유지하는 방식이다. 커서가 위치해있는 동안은 읽기 락이 유지되므로 커서가 위치해있는 동안은 다른 트랜잭션에 의해 데이터가 수정되지 않고, 안정된 데이터를 보인다.
심지어 트랜잭션을 선언할 때 성능을 위해 고립성 수준을 선택할 수도 있다. Serializable, Repeatable read, Read committed, Read uncommitted 네 방식 중 Serializable을 제외하고는 직렬 가능한 스케쥴로 실행하지 않는다. 상용 시스템에서는 기본적으로 Read committed 방식을 기본 수준으로 선택한다. 각 수준별 차이는 다음과 같다. (Snapshot이라는 소개하지 않는 방식도 포함되어 있다.)
 출처 : http://thesqlgirl.com/2016/11/01/sql-transaction-isolation-levels/
출처 : http://thesqlgirl.com/2016/11/01/sql-transaction-isolation-levels/Read uncommitted 방식은 읽기 연산에서 록을 잡지 않지 때문에 읽은 데이터에 신빙성이 전혀 없다. 그러나 집계 연산 같은 작업을 위해서는 유용하게 쓰일 수 있다. Read committed인 경우에는 록을 잡고 읽은 후에 즉시 록을 풀기 때문에 다른 값을 수정하는 도중 문제가 생길 수 있다. Repeatable read는 한번 읽은 값은 트랜잭션 끝까지 유지가 되므로 처음 트랜잭션이 시작할 때의 값은 그대로 읽을 수 있으나 트랜잭션 실행 도중 생긴 변화는 읽을 수 없다.
장애(Failure)와 복구(Recovery)
장애는 트랜잭션 장애, 시스템 장애, 디스크 장애 세 가지로 나뉜다. 트랜잭션 장애는 데드락이나 사용자의 요구, 시스템의 판단 등에 의해 트랜잭션을 철회시키면서 발생할 수 있는 장애이다. 시스템 장애에는 정전으로 시스템이 변경 사항을 저장 장치에 쓰기 전 컴퓨터가 아예 꺼져버리거나 운영 체제 문제로 인해 DB 시스템이 종료되는 장애 등이 포함된다. 디스크 장애는 하드웨어 결함 등으로 인해 디스크 내용이 소실되는 장애이다. 장애는 예고 없이 다양한 형태로 발생할 수 있다. 장애가 발생하면 시스템이 복구 작업을 해야 하며, 복구 알고리즘은 정상 상태에 복구를 위해 미리 수행하는 작업과 장애 발생 후 복구를 위해 수행되는 작업으로 나뉜다.
정상 상태에 복구를 위해 미리 수행하는 작업은 기본적으로 로그 쓰기이다. 로그는 안전 저장 장치(Stable storage)라는 곳에 쓰는데, 안전 저장 장치는 어떠한 장애가 발생하여도 저장 내용이 상실되지 않는다는 가정을 하는 가상적인 저장 장치이다. 이러한 가정 없이는 저장 내용에 대한 최소한의 안정성을 기대할 수 없기 때문에 복구에 대해 논하기 어렵다. 실제로 안정 저장 장치는 RAID(Redundant Array of Independent Disks)나 중복 분산 저장 등으로 구현된다.
데이터의 위치
DB 시스템에서는 동일 데이터가 디스크 블록, 메인 메모리 상의 데이터 버퍼 블록, 트랜잭션 프로세스의 메모리 세 곳에 위치할 수 있다. 디스크 블록에 있는 데이터는 시스템이 종료되거나 메모리가 고장이 나더라도 손상되지 않는다.
DB의 데이터는 기본적으로 디스크 블록에 존재하며 DBMS에 의해 필요한 경우에만 시스템 버퍼에 로드한다. 트랜잭션은 시스템 버퍼에 있는 값을 직접 참조하지 않고 트랜잭션의 메모리 공간에 복사한 값을 사용한다. 트랜잭션이 데이터에 쓰기 연산 시 시스템 버퍼에 반영되고 DBMS는 시스템 버퍼 관리 원칙에 의해 시스템 버퍼의 데이터를 디스크 블록에 쓰기 작업을 수행한다.
로그(Log)
상용 DB 시스템은 복구를 위해 로그 방식을 사용한다. 로그 방식의 핵심은 DB에 변화가 생기기 전 변화에 대한 기록을 안전 저장 장치에 저장하는 원칙을 지키는 것이다. 이러한 원칙을 WAL(Write Ahead Logging) 원칙이라고 한다. 구체적으로 로그를 어떻게 남기는지에 대한 방법은 여러 가지가 존재할 것이다. 디스크와 메모리 간의 데이터 이동은 디스크 블록 단위로 이뤄지고, 로그를 저장하는 로그 블록도 디스크 블록 단위로 저장된다. 또한, 여러 트랜잭션이 함께 로그를 남기기 때문에 로그 블록에는 여러 트랜잭션의 로그가 함께 저장되어 있다.
항상 처음부터 모든 로그를 확인하여 복구하는 것은 시간이 너무 오래 걸리므로 검사점(Checkpoint)을 두어 해당 시점까지는 장애가 없었다는 증표를 남겨둔다. 검사점을 만들 때는 아직 디스크에 반영되지 않은 모든 로그들과 변경된 데이터들을 디스크에 반영시킨다. 메모리와 디스크의 내용을 동일하게 만드는 것이다. 검사점을 만들고 나면 장애가 발생했을 때 검사점 이후의 로그들만 이용하여 복구 작업을 수행하면 된다.
장애가 발생한 뒤 복구를 위한 작업에 대해 로그와 관련된 내용만 설명하면 다음과 같다. 장애 발생 후에는 로그와 디스크에 저장된 데이터만이 존재한다. 먼저 검사점 이후의 로그들을 분석하여 완료되었지만(committed) 디스크에 반영되지 않아 재연산을 해야 할 트랜잭션들을 redo 리스트에 추가하고 시작하였지만 완료되지 않았던 트랜잭션을 undo 리스트에 추가한다. 그리고 마지막 로그부터 검사점까지 역방향으로 undo 리스트에 존재하는 작업을 undo 하고, 다시 검사점부터 정방향으로 redo 리스트에 있는 작업들을 redo 한다.
로그 블록을 디스크에 쓰는 것은 시간이 많이 소요되기 때문에 버퍼링 후 디스크에 반영한다. 트랜잭션을 완료 처리하기 전에 안전 저장 장치에 로그 쓰기 작업이 무조건 선행되어야 하기 때문에 버퍼링 되는 트랜잭션 여러 개가 동시에 완료되기도 한다.
데이터 페이지 버퍼링(Data Page Buffering)
데이터 블록이 디스크에 쓰이는 동안은 해당 데이터 블록 내의 데이터가 수정되지 않도록 해야 한다. 이전의 락과 달리 여기서는 래치(Latch) 또는 세마포어를 사용한다. 디스크 쓰기 속도는 매우 느리기 때문에 효율을 위해 데이터 페이지도 버퍼링 한다. 현대 운영 체제는 대부분 가상 메모리 기법을 사용하는데, 이 때문에 듀얼 페이징(Dual-paging) 문제가 발생할 수 있다. 듀얼 페이징은 메모리의 내용이 스왑핑(Swapping)에 의해 이미 디스크에 쓰인 상태에서 그 데이터를 디스크에 쓰려고 할 경우 데이터 페이지가 메모리에 다시 로드된 뒤, 디스크에 다시 쓰이는 문제이다. 이러한 문제가 생기지 않기 위해서는 운영 체제가 DB 시스템의 데이터 블록과 관련된 메모리를 스왑 하려는 경우 DB 영역에 쓰기 하도록 협의되도록 해야 한다.
데이터 페이지 버퍼링에는 Steal 정책과 Force 정책이 있다. Steal 정책은 트랜잭션이 완료되기 전 디스크 블록에 변경 사항이 쓰일 수 있는지에 대한 정책이고, Force 정책은 트랜잭션이 완료되었을 때 항상 디스크 블록에 변경 사항을 적용해야 하는지에 대한 정책이다. Force 정책은 매번 트랜잭션이 완료될 때마다 디스크 접근을 요구하므로 성능에 큰 영향을 끼칠 수 있다. Steal/Force 정책을 사용하는 시스템이라면 복구 작업 시 undo 작업만 하면 되고, NotSteal/NotForce 정책을 사용하는 시스템이라면 redo 작업만 하면 되기 때문에 어떤 정책을 사용하는 시스템인지에 따라 복구 작업에 차이가 있다고 봐야 할 것이다.
원격 백업(Remote Backup)
누구도 예상하지 못했던 천재지변에 의해 시스템 컴퓨터가 손상을 입을 수도 있다. 항상 예로 드는 것이 9.11 테러다. 9.11 테러로 공격받은 빌딩에는 많은 시스템 장비들이 있었고, 테러로 인해 손상되었지만 원격 백업이 있었기 때문에 복구될 수 있었다. 원격 백업 시스템은 주 시스템(Primary system)이 있는 곳 외에도 다른 지역에 백업 시스템(Backup system)을 둬서 시스템 가용성을 높인다. 주 시스템에 문제가 생겨 백업 시스템이 주 시스템 역할을 수행해야 할 경우 백업 시스템은 로그들을 이용하여 복구 연산을 하여 주 시스템과 같은 상태로 만든 뒤 원래 시스템의 역할을 수행하면 된다.
백업 시스템이 빠르게 주 시스템 역할을 수행할 수 있도록 하려면 백업 시스템이 주 시스템으로부터 받은 로그를 즉시 적용해둬야 하며, 이를 Hot spare라고 한다. 백업 시스템 환경에서 트랜잭션의 지속성을 보장하기 위해서는 트랜잭션의 완료 로그가 필요한데, 백업 시스템에 그 로그가 기록되는 데는 시간이 걸린다. 백업 시스템에 로그를 적용시키는 방식으로 One-safe, Two-very-safe, Two-safe 방식이 있다. One-safe 기법은 트랜잭션이 완료되었을 때 주 시스템에만 적용이 완료되면 되는 방식이다. 가장 빠르다. Two-very-safe 기법은 트랜잭션이 완료되었을 때 백업 시스템들 모두에 적용이 완료되어야 하는 방식으로, 가장 느리다. Two-safe 방식은 하나의 백업 시스템에만 적용되면 되는 방식으로 Two-very-safe보다 느슨하지만 더 빠를 것이다.
원격 백업 시스템의 대안으로는 분산 데이터베이스 방식이 있다.
저장 장치(Storage)
DB 시스템은 저장 장치와 매우 밀접한 관계를 가진다. 저장 장치의 종류도 여러 가지고, 저장 장치를 시스템과 연결하는 방법 또한 여러 가지다. 흔히 많이 쓰이는 SATA 인터페이스로 연결되는 것뿐만 아니라 네트워크 상으로 연결되는 SAN(Storage Area Network), NAS(Network Attached Storage) 등이 있다. 기존에는 HDD를 많이 썼었기 때문에 디스크 성능 평가 또한 중요한 이슈 중 하나였으나 서서히 SSD를 사용하는 시스템들이 많이 늘어나고 있고, 이전의 운영 체제 편에서 디스크 스케쥴링에 대한 내용을 정리하였기 때문에 이 글에서는 설명하지 않겠다.
DB 시스템에서 저장 장치에 대해 생각할 때는 거의 무조건 RAID 시스템을 생각하면 된다. 보통 RAID 0 혹은 5가 많이 쓰인다. RAID는 낭비처럼 보일지 모르지만 시스템 장애가 생겨 데이터를 잃었을 때 문제 해결을 위한 비용을 생각해보면 절대 비싼 것이 아니다.
파일/레코드 구성(File/Record Organization)
DB는 여러 파일들로 구성되고, 파일은 여러 레코드로 구성되며, 레코드는 여러 필드로 구성된다. 레코드를 저장하는 가장 간단한 방법은 고정 길이 레코드(Fixed length record)이다. 모든 레코드의 길이가 동일하다고 가정하지만, 실제로 이런 경우는 잘 없다. 보통은 가변 길이 레코드(Variable length record)로 저장되며, 이 방식은 레코드 앞에 레코드의 속성별 offset과 길이를 나타내는 정보가 존재한다.
레코드들은 페이지에 위치하게 되는데, 그 구성 방법으로는 슬롯 페이지 구조(Slotted Page Structure)가 널리 쓰인다. 페이지의 헤더에는 페이지의 ID, 소유자, 남은 공간 등 여러 정보와 슬롯(slot) 테이블이 있다. 각 슬롯은 실제 레코드의 주소를 가진다. 페이지 내에서 레코드가 이동할 때는 슬롯 번호가 바뀌지는 않고 슬롯에 있는 페이지 내 주소만 변경하면 된다. 외부에서는 페이지 번호와 슬롯 번호만 알면 해당 레코드가 접근할 수 있다.
 출처 : 큐브리드
출처 : 큐브리드파일 내 레코드 구성 방법은 힙 파일, 순차 파일, 해시 파일로 나뉜다. 힙 파일은 레코드 간에 순서 없이 여유 공간 아무 곳에 레코드가 위치한다. 순차 파일은 레코드가 파일 내에 순차적으로 존재하도록 구성하여 각 레코드를 순차적으로 접근할 때 효율적이다.
일반적으로 단일 관계에 속하는 레코드는 한 물리적 파일에 저장된다. 그러나 DB는 조인 등의 연산으로 여러 관계의 데이터를 함께 사용하는 경우가 잦기 때문에 다중 테이블 집약(Multitable clustering) 방식으로 저장하기도 한다.
색인(Index)
DB 튜닝의 꽃이라 볼 수 있는 색인에 대해 알아본다. 색인의 개념과 주요 색인 자료 구조인 B+ 트리, 확장 해싱, 비트맵에 대해 살펴볼 것이다. 색인의 목적은 데이터를 빨리 찾는 것이다. 정렬 색인(Ordered index)은 키를 기준으로 정렬되어 있으며, 해쉬 색인(Hash index)은 정렬되어 있지 않다.
어떤 색인을 사용하는 게 좋을지에 대해 평가하기 위해 사용될 질의(Query) 종류를 먼저 고려해야 한다. 질의는 특정 값의 레코드를 찾는 Exact match 질의와 일정 범위에 속하는 레코드를 찾는 Range 질의로 나뉜다. 당연히 정렬 색인은 키에 대해 정렬되어 있기 때문에 Range 질의에 적합하고, 해쉬 색인은 정렬되어 있지 않기 때문에 Range 질의에 적합하지 않다.
주 색인(Primary index)은 실제 파일의 레코드 순서와 동일한 순서로 존재하는 색인이고, 이차 색인(Secondary index)은 실제 파일 내 레코드 순서와 관련 없이 키에 대해 정렬된 상태로 존재하는 색인이다. 주 색인은 단 하나만 존재할 수 있고, 이차 색인은 여러 개를 만들어 둘 수 있다. 밀집 색인(Dense index)은 모든 레코드에 대한 색인 레코드가 존재하고 희소 색인(Sparse index)은 일부 레코드에 대해서만 색인 레코드가 존재한다. 희소 색인은 키를 기준으로 데이터 레코드들이 정렬되어 있지 않으면 의미가 없다. 성능 등의 목적으로 다단계 색인(Multilevel index)을 구성해서 쓰는데, 색인은 항상 정렬되어 있으므로 상위 수준에 희소 색인을 적용할 수 있다. 이차 색인은 데이터 레코드 순서와 관련 없이 존재하는 색인이므로 반드시 밀집 색인이어야 한다.
데이터 레코드가 삽입되거나 삭제되는 경우에도 색인 파일에 대한 갱신이 이뤄져야 한다. 그렇기 때문에 색인을 만들어두는 것은 오버헤드가 발생한다고 하는 것이다. 그러나, 색인 유무에 따라 검색 속도의 차이가 매우 크기 때문에 많은 경우에 색인은 꼭 필요하다.
B+ 트리
B+ 트리는 균형 트리(Balanced tree) 상태를 유지하는 자료 구조이다. 많은 상용 시스템에서 색인을 위한 자료 구조로 쓰인다. 데이터에 변화가 일어나도 지역적인 변화만 있으면 되기 때문에 색인 유지에 용이하다. 트리 하면 이진 트리를 주로 생각하지만 B+ 트리는 자식을 매우 많이(예를 들면 1000개) 가지도록 만든다. 즉, 좌우로 매우 뚱뚱한 트리가 된다. B+ 트리의 노드 크기는 보통 4KB, 8KB, 16KB 정도인데, 만약 블록의 크기가 4KB이고 탐색 키의 크기가 40B라고 하면 색인 노드의 fanout(포인터 개수)는 100개가 되며, 100만 개의 노드를 가지는 트리의 깊이(Depth)는 4로 매우 작다. 깊이를 작게 하는 것이 중요한 이유는 디스크 접근을 줄이기 위해서이다. 색인 또한 디스크에 저장되기 때문이다.
B+ 트리의 단말 노드는 실제 레코드를 가리키는 포인터를 가진다. 또한, 다음 순서의 색인 노드를 가리키는 포인터도 가진다. 이렇게 함으로써 Range 질의에 효과적인 모습을 보인다. 조건에 맞지 않을 때까지 포인터를 따라 다음 순서의 레코드를 차례로 탐색하면 되기 때문이다.
B+ 트리가 균형 상태를 유지하도록 하는 삽입, 삭제 연산의 자세한 설명은 다음 링크를 참고.
확장 해싱(Extendible Hashing)
정적 해싱(Stati hashing) 방법의 문제는 균일하고(Uniform) 임의적인(Random) 해시 함수를 찾기 어렵기 때문에 점점 데이터가 많아짐에 따라 충돌이 많이 일어나게 되고, 충돌로 인한 성능 저하가 발생한다는 것이다. 확장 해싱은 해시 함수가 동적으로 변하게 함으로써 이 문제를 해결한다. 해시 방법은 Exact match 질의에만 적합하다. 해시 결과 기존 데이터 레코드의 순서와 전혀 다른 순서가 되기 때문이다.
확장 해싱에서는 해싱 결과 값의 앞쪽 bit를 이용하여 버킷 주소를 결정한다. 버킷은 두 개로 분리되거나 두 개가 합쳐져 하나의 버킷이 될 수 있다. 확장 해싱의 작동 원리에 대한 자세한 설명은 다음 링크를 참고.
비트맵(Bitmap)
비트맵 색인은 탐색 키의 종류가 적을 때 다중 속성에 대한 질의에 유용한 색인이다. 예를 들어, 글의 상태와 같이 공개, 비공개 정도로 적은 종류의 키가 되거나, 급여를 (달러 기준) 10000 단위로 범주를 나눠놓은 경우가 해당된다.
비트맵 색인은 다중 속성에 대한 조건을 bit 연산하여 조건을 결과 값을 만든다. 미리 준비되어 있는 비트맵 색인들도 마찬가지로 bit 연산하여 결과 값을 만들면 조건을 만족하는 레코드의 위치들에 대한 bit 벡터가 만들어진다. 비트 연산은 매우 빠르게 수행 가능하고, 용량 또한 작기 때문에 앞서 언급한 바와 같이 탐색 키의 종류가 적다면 매우 유용한 색인이다.
비트맵 색인에 대한 좀 더 자세한 설명은 다음 링크를 참고.
질의 처리(Query Processing)
DBMS에서 질의 처리 과정에 대해 알아본다. 질의가 입력되면 파싱 및 번역 단계에서 구문 검사, 타입 검사, 권한 검사 등을 한 뒤, 시스템에서 처리하기 쉬운 형태로 변환한다. 시스템마다 차이는 있지만 주어진 SQL과 동일한 결과를 주는 관계 대수 형태가 된다. 표현식은 질의 최적화 도구를 거쳐 더 빠르게 실행 가능한 형태로 보완된다. 이때, 질의 최적화 도구는 최적화를 위해 통계 정보가 담긴 카탈로그(Catalog)를 참고한다. 최적화를 마친 뒤 만들어진 실행 계획이 실행 엔진에서 실행된 후 결과를 사용자에게 반환한다. 아래 그림은 그 과정을 다이어그램으로 나타낸 것이다.
 출처 : http://sungsoo.github.io/2014/05/27/query-processing.html
출처 : http://sungsoo.github.io/2014/05/27/query-processing.html질의 최적화는 매우 중요하다. 컴파일러도 최적화 옵션을 사용한 것과 아닌 것의 속도 차이가 많이 나는 것처럼 DB 시스템도 최적화를 적용한 질의와 최적화를 적용하지 않은 질의의 실행 속도에 큰 차이를 보인다. 비싼 연산인 조인 연산은 구현 알고리즘도 여러 가지이고, 색인을 어떻게 사용하는지도 성능에 큰 영향을 끼치는 요소이다. 심지어 어떤 경우는 색인을 아예 사용하지 않는 것이 더 빠른 경우도 있다. (교수님께서 수업 시간에 말씀하시길 조건 대상이 데이터의 10%를 넘어가면 보통 색인을 사용하지 않는 것이 더 빠른 경향을 보였었다고 하셨다.) 질의 최적화를 위해서는 당연히 예측을 잘 하는 것이 중요하고, 예측을 잘 하기 위해 통계 정보가 있는 카탈로그를 참고한다.
질의 비용(Query cost)에 영향을 끼치는 요소는 물론 다양하지만, 그중에서도 가장 큰 요소는 디스크 접근이며, 보통 다른 비용을 압도(Dominant)한다. 앞으로 질의 처리 비용을 계산할 때는 디스크 접근 횟수와 블록 전송 시간을 위주로 단순화하여 계산할 것이다. 물론 질의 결과를 디스크에 쓰는 일도 일어나지만, 이는 버퍼 관리 정책 등에 의해 계산하기 어려운 부분이므로 배제한다.
선택 연산(Select Operations)
가장 기초적인 선택 연산은 관계의 처음부터 끝까지 모두 선형 탐색하는 방법이다. 데이터 레코드가 디스크 내에 순차적으로 위치하고 있다는 가정 하에 첫 데이터 레코드가 존재하는 디스크 블록을 찾는 시간과 전체 데이터 블록을 전송하는 시간이 든다.
주 색인을 이용하여 어떤 키 값을 가지는 레코드를 찾는 연산(Exact match 질의)은 B+ 트리를 탐색하는 시간이 든다. B+ 트리의 단말 노드에서 데이터 노드까지 탐색하여야 하기 때문에 (트리의 깊이 + 1)만큼의 디스크 탐색 및 데이터 전송 시간이 요구된다. 만약 조건을 만족하는 레코드가 여러 개라면 조건을 만족하는 레코드가 들어있는 블록 개수만큼의 전송 시간이 더 요구된다. 만약 이차 색인이라면 데이터 레코드의 위치가 순서대로 있지 않기 때문에 매 레코드마다 디스크 탐색 시간이 더 요구될 것이다.
비교 연산이라면 거의 대부분 조건을 만족하는 레코드가 여러 개다. 주 색인에 대한 경우 조건을 만족하는 레코드를 찾은 뒤 선형 탐색을 하면 되지만, 이차 색인은 선형 탐색이 되지 않기 때문에 더 많은 시간이 요구된다. 이차 색인의 경우 디스크 탐색 시간이 매우 많이 들 수 있기 때문에 색인을 사용하지 않는 것이 더 빠를 수도 있다.
여러 조건에 대한 논리곱 선택 연산인 경우 첫 조건이 중요하다. 첫 조건 결과 레코드가 가장 적어지도록 해야 이후 조건들을 빠르게 적용 가능하다. 만약 조건 결과를 만족하는 레코드의 양이 메인 메모리 크기를 초과한다면 조건 결과를 디스크에 다시 써야 하기 때문에 시간 차이가 많이 발생할 것이다. 조건에 대한 다중 키 색인이 있다면 더 좋겠지만, 그렇지 않은 경우가 많다. 단일 속성 색인을 이용하는 경우 색인별로 조건을 만족하는 레코드 리스트를 만들고, 리스트들에 대한 교집합 연산을 거쳐 최종 레코드 리스트를 만든 뒤 레코드를 읽어올 수 있다. 논리합 선택 연산일 경우 이전처럼 각 조건을 만족하는 리스트를 구한 뒤 합집합 연산을 거칠 수도 있지만, 선형 탐색이 나은 경우가 많다. 부정 조건은 매우 적은 수의 레코드가 조건을 만족하는 경우가 아니라면 선형 탐색이 더 낫다.
정렬(Sorting)
메인 메모리에 데이터가 모두 로드될 수 있다면 당연히 널리 알려진 퀵 정렬 혹은 힙 정렬 등을 사용할 것이다. 하지만 DB에서는 메인 메모리보다 많은 데이터를 다뤄야 하는 경우를 상정해야 하며, 이 때는 외부 병합 정렬(External merge sort) 방법이 적합하다. 외부 병합 정렬은 부분적으로 정렬하고 병합하기를 반복하는 방법으로, 기존의 병합 정렬 아이디어를 생각하면 쉽다. 외부 병합 정렬에서 부분적으로 병합된 데이터의 양도 메인 메모리 크기보다 클 수 있다. 그러나 각 부분을 병합하기 위해서는 순차 탐색을 하면 되기 때문에 메모리 크기보다 많은 데이터를 정렬할 수 있다. 다음은 위키백과에서의 설명이다.
예를 들어, 900MB의 데이터를 100MB의 RAM을 사용하여 정렬을 해야 한다고 해보자.
1. 100MB 데이터를 주메모리에 읽어 들이고, quicksort와 같이 일반적인 알고리즘을 사용하여 정렬한다.
2. 정렬된 데이터를 디스크에 쓴다.
3. 1,2번 과정을 9번 반복한다. 그러면 100MB짜리 파일이 9개 생긴다.
4. 9개의 파일에서 각각 처음부터 10MB 씩을 메모리(입력 버퍼)에 로딩한다. 10MB의 출력을 위한 버퍼도 만들어둔다.
5. 9 way merge를 수행하고 결과를 출력 버퍼에 쓴다. 출력 버퍼가 차면 파일에 쓰고, 출력 버퍼를 비운다. 9개의 입력 버퍼가 비워지면, 다음 10MB를 읽는다.
초기 분할을 위해 모든 블록에 대해 읽고 쓰기를 해야 하므로 총 데이터 양의 2배만큼의 블록 전송 비용이 들고, 병합을 위한 pass가 log를 취한 만큼 발생한다. (병합 정렬의 원래 시간 복잡도를 생각하자.) 각 부분을 읽고 쓸 때마다 디스크 탐색 시간도 발생한다. 좀 더 정리된 계산은 다음 링크를 참고.
조인 연산(Join Operations)
조인 연산을 수행하는 방법은 중첩 루프 조인(Nested loop join), 블록 중첩 루프 조인(Block nested loop join), 색인 중첩 루프 조인(Indexed nested loop join), 병합 조인(Merge join), 해시 조인(Hash join)으로 나뉜다. 각 방법을 살펴보자.
중첩 루프 조인은 입력된 두 관계에 카티전 곱한 연산에 주어진 조건을 만족하는 레코드를 찾는 방법이다. 일반적인 이중 루프와 형태가 같다. 최악의 경우 한 관계 내에 존재하는 모든 레코드에 대해 조인 대상 관계 전체를 읽어야 한다. 가장 좋은 경우는 두 관계 모두 메모리에 로드할 수 있는 경우이다. 이 경우 메모리에서 바로 계산 가능하므로 두 관계의 데이터 블록을 전송하는 시간만이 발생한다.
중첩 루프 조인은 레코드 단위로 생각한 것이고, 실제로는 디스크 접근 연산이 적은 블록 중첩 루프 조인 방법이 사용된다. 관계의 데이터에 해당하는 블록만큼의 디스크 접근으로 접근 횟수가 많이 줄어든다. 가장 나쁜 경우는 루프상으로 외부에 해당하는 관계의 블록마다 내부에 해당하는 관계의 모든 블록을 읽어야 하는 경우이다. 외부 테이블의 블록 개수만큼 내부 테이블을 탐색해야 하므로 시간이 많이 든다. 최대한 외부 테이블의 블록을 많이 메모리에 올려둬야 내부 테이블의 탐색 시간을 줄일 수 있다.
색인 중첩 루프 조인은 내부 테이블에 색인이 존재하는 경우 가능하다. 내부 테이블의 블록마다 색인 블록을 디스크에서 찾아야 하는 경우 최악의 상황이 된다. 차라리 이 경우엔 색인을 사용하지 않는 것이 더 빠르다.
병합 조인은 동등 조인과 자연 조인 연산을 하려 할 때 조인 연산을 수행할 테이블이 정렬되어 있는 경우에 사용 가능하다. 만약 정렬되어 있지 않다면 외부 병합 정렬 알고리즘을 수행해야 한다. 병합 조인을 할 때는 두 테이블을 차례로 한 번 읽기만 하면 되기 때문에 효율적이다. 만약 정렬 시간이 많이 들지 않는다면 좋은 성능을 기대할 수 있다.
해시 조인 또한 동등 조인과 자연 조인에만 적용 가능한 방법이다. 조인 대상 테이블에 해시 함수를 적용하여 작은 부분으로 나눈 뒤, 같은 부분 내의 데이터끼리만 조인 연산을 수행하는 것이 핵심 아이디어이다. 각 분할을 메인 메모리에 로드한 뒤 조인 연산을 수행할 수 있기 때문에 좋은 성능을 기대할 수 있다. 만약, 각 분할이 메인 메모리에 모두 로드될 수 없다면 해시 조인을 쓰지 않는 것이 나을 수 있다.
기본적으로 조인 연산에 있어 가장 좋은 상황은 하나의 테이블이라도 메인 메모리에 모두 로드될 수 있는 상황이다. 이 경우 상대 테이블을 한 번 순차 탐색을 수행하기만 하면 조인 연산을 마칠 수 있기 때문에 가장 빠르다. 조인 연산에 대한 좀 더 종합적이고 자세한 설명은 다음 링크를 참고.
수식 평가(Evaluation of Expressions)
지금까지 살펴본 것은 관계 대수의 각 연산이었다. 질의 수행은 관계 대수의 결과에 또다시 관계 대수를 연산한다. 연결된 연산은 구체화(Materialization), 파이프라이닝(Pipelining) 방식으로 연산될 수 있다. 구체화 방식은 각 단계의 관계 대수 중간 결과를 임시 저장하여 다음 연산에게 제공하는 방법이다. 중간 결과를 매번 디스크에 쓰고 다음 관계 대수로 읽어 들여야 하기 때문에 비용이 많이 든다. 파이프라이닝 방식은 중간 결과를 디스크에 쓰지 않고 바로 다음 관계 대수에게 전달하는 방법으로 디스크 접근이 발생하지 않아 효과적이지만 모든 경우에 가능한 방식은 아니다. 정렬 연산만 생각해봐도 중간 결과를 다음 관계 대수에게 전달할 수 없다.
파이프라이닝은 요구 주도 방식과 생산 주도 방식으로 나뉜다. 요구 주도 방식은 상위 수준 연산자가 하위 수준 연산자에게 계산 결과를 요구하는 방식으로 Pull 모델이다. 호출 간에 상태를 유지해야 하며, 상태에 따라 다음 입력 요청을 처리한다. 반면, 생산 주도 방식은 하위 수준 연산자가 상위 수준 연산자에게 계산 결과를 주는 방식으로 Push 모델이다. 생산 주도 방식은 연산자 간의 출력 버퍼를 유지해야 한다.
데이터베이스 개발 관점 정리
지금까지 DB 시스템을 개발하기 위해 생각해봐야 할 점들을 살펴보았다. 시스템에서 논리적 작업 단위인 트랜잭션의 성질과 여러 트랜잭션을 동시에 실행하기 위한 동시성 제어, 장애 대응을 위한 복구, 데이터가 저장될 저장 장치, 질의 처리 속도 향상을 위한 색인, 질의 처리의 자세한 방법에 대해 알아보았다.
트랜잭션은 ACID 성질을 충족해야 한다. ACID 성질을 충족하면서도 자원을 효율적으로 사용하기 위해 여러 트랜잭션을 동시에 실행하고 싶다. 문제없이 동시 실행을 하기 위한 규약으로 두 단계 락킹 규약, 트리 기반 락킹 규약을 알아보았다.
장애가 발생했을 때 복구를 하기 위해서는 평소에 수행하는 작업들에 대한 로그가 필요하다. 장애가 발생한 뒤에는 로그를 기반으로 undo, redo를 수행하면 된다. 또한, 시스템이 망가질 것을 대비하여 원격 백업 시스템을 둠으로써 시스템 가용성을 향상할 수 있다.
저장 장치 특성과 DB에서 데이터 관리를 위해 파일을 어떻게 구성하는지도 알아보았다. 데이터 레코드들은 페이지에 소속되며, 페이지 내에는 헤더와 각 레코드를 가리키는 슬롯들로 구성되어 있다.
색인은 질의 처리 속도 향상의 핵심이다. 어떤 질의를 처리할 지에 따라 다른 색인을 사용해야 효과적이다. 질의 종류는 크게 Exact match 질의와 Range 질의로 나뉜다. 색인을 유지 및 사용하는 것은 추가적인 디스크 접근을 요구하기 때문에 어떤 경우에는 색인을 사용하지 않는 것이 나을 수도 있다.
DBMS는 질의 처리를 위해 몇 단계를 거친다. 더 빠른 수행을 위해 훌륭한 성능의 최적화 도구가 꼭 필요하다. 각 연산에 있어 가장 중요한 성능 척도는 디스크 접근 횟수이다. 메모리 내의 연산에 비해 디스크 접근이 압도적으로 느리기 때문이다. 주요 질의 연산으로 선택 연산, 정렬 연산, 조인 연산이 있다. 질의는 관계 대수로 변환되는데, 각 관계 대수는 자신의 처리 결과를 상위 수준 관계 대수에게 제공한다.
지금까지 데이터베이스 사용과 개발에 있어 생각해봐야 할 점들에 대해 알아보았다. 매 항목이 방대한 내용이지만 짧은 글에서 모두 설명할 수는 없기 때문에 참고 자료를 많이 링크하였다. DB 시스템을 직접 개발할 일이 없더라도 시스템이 어떻게 만들어지는지 알아두는 것은 시스템을 잘 사용하기 위한 능력에 도움이 된다고 본다. 다음 편에서는 통계 기반 데이터 마이닝을 다룬다.