import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static int N;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
int number = 0;
int count = 0;
for (int i = 0; i < N; i++) {
number = Integer.parseInt(st.nextToken());
if (number == 1)
continue;
boolean flag = true;
for (int j = 2; j <= Math.sqrt(number); j++) {
if (number % j == 0) {
flag = false;
break;
}
}
if (flag) {
count++;
}
}
System.out.println(count);
}
}
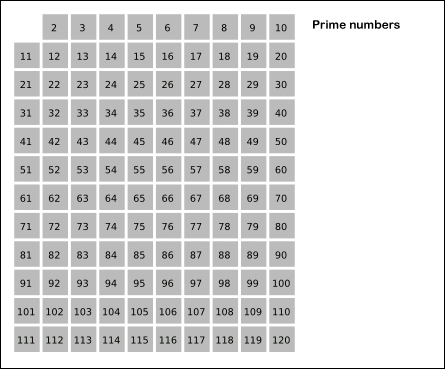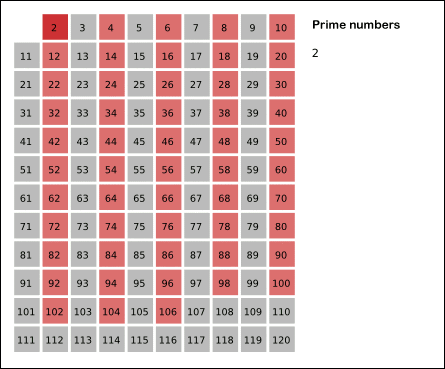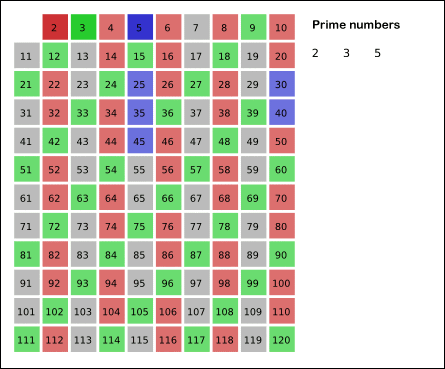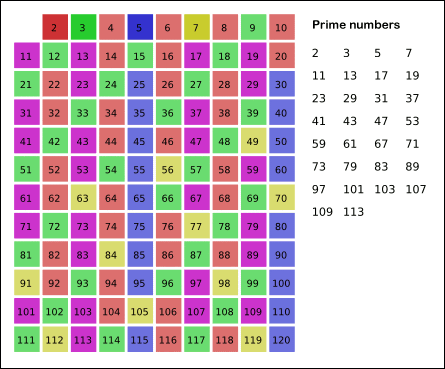
우리는 앞서 조화수를 통해 점근적 시간 복잡도 O(NlogN) 이라는 시간 복잡도를 얻었다.
이 의미는 x개의 수에 대해 2일 때 체크하는 개수인 (x/2), 3일 때 체크하는 개수인 (x/3), ... 이렇게 체크를 하게 된다.
하지만 우리가 알고싶은 것은 이미중복되는 수들은 검사하지 않는다는 것이다. 이 의미는 무엇일까? 결국 검사하는 수는 소수로 판정 될 때 그의 배수들을 지우는 것이라는 것이다. 이 말은 구간 내의 소수의 개수를 알아야 한다는 뜻이기도 하다.
근데, 소수가 규칙성이 있는가? 이 것은 아직까지도 풀지못한 것이다. 이를 찾고자 가우스는 15살 때 하나하나씩 구하면서 x보다 작거나 같은 소수의 밀도에 대해 대략1 / ln(x)라는 것을 발견하게 되는데 증명을 못했다. (이를가우스의 소수 정리라고 한다)
즉, 위를 거꾸로 말하면 x번째 소수는 xlog(x) 라는 의미가 되지 않겠는가? 즉, 우리는 앞서 1/x 의 합을 구했지만, 실제로 중복되는 수가 제외된다면 x는 소수만 된다는 의미고, 이는 소수의 역수 합이다. (1/2 + 1/3 + 1/5 + 1/7 + ⋯ ) 이런식으로 말이다.
월드전자는 노트북을 제조하고 판매하는 회사이다. 노트북 판매 대수에 상관없이 매년 임대료, 재산세, 보험료, 급여 등 A만원의 고정 비용이 들며, 한 대의 노트북을 생산하는 데에는 재료비와 인건비 등 총 B만원의 가변 비용이 든다고 한다.
예를 들어 A=1,000, B=70이라고 하자. 이 경우 노트북을 한 대 생산하는 데는 총 1,070만원이 들며, 열 대 생산하는 데는 총 1,700만원이 든다.
노트북 가격이 C만원으로 책정되었다고 한다. 일반적으로 생산 대수를 늘려 가다 보면 어느 순간 총 수입(판매비용)이 총 비용(=고정비용+가변비용)보다 많아지게 된다. 최초로 총 수입이 총 비용보다 많아져 이익이 발생하는 지점을 손익분기점(BREAK-EVEN POINT)이라고 한다.
A, B, C가 주어졌을 때, 손익분기점을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 A, B, C가 빈 칸을 사이에 두고 순서대로 주어진다. A, B, C는 21억 이하의 자연수이다.
출력
첫 번째 줄에 손익분기점 즉 최초로 이익이 발생하는 판매량을 출력한다. 손익분기점이 존재하지 않으면 -1을 출력한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static int A,B,C,N;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
A = Integer.parseInt(st.nextToken());
B = Integer.parseInt(st.nextToken());
C = Integer.parseInt(st.nextToken());
if(C-B>0) {
N = (A / (C-B)) +1;
} else {
N = -1;
}
System.out.println(N);
}
}
두 자연수 A와 B가 있을 때, A%B는 A를 B로 나눈 나머지 이다. 예를 들어, 7, 14, 27, 38을 3으로 나눈 나머지는 1, 2, 0, 2이다.
수 10개를 입력받은 뒤, 이를 42로 나눈 나머지를 구한다. 그 다음 서로 다른 값이 몇 개 있는지 출력하는 프로그램을 작성하시오.
입력
첫째 줄부터 열번째 줄 까지 숫자가 한 줄에 하나씩 주어진다. 이 숫자는 1,000보다 작거나 같고, 음이 아닌 정수이다.
출력
첫째 줄에, 42로 나누었을 때, 서로 다른 나머지가 몇 개 있는지 출력한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws NumberFormatException, IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// StringTokenizer st = new StringTokenizer(br.readLine());
boolean[] arr = new boolean[42];
int answer = 0;
int count = 0;
for (int i = 0; i < 10; i++) {
arr[Integer.parseInt(br.readLine()) % 42] = true;
}
for (int i = 0; i < 42; i++) {
if (arr[i]) {
count++;
}
}
System.out.println(count);
}
}
제수가 42로 고정이기 때문에 42바이트 boolean 형식의 배열을 선언하여
각 나머지를 해당 자리수 배열에 저장한뒤 true 개수를 출력
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashSet;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// StringTokenizer st = new StringTokenizer(br.readLine());
HashSet<Integer> hs = new HashSet<Integer>();
for (int i = 0; i < 10; i++)
hs.add(Integer.parseInt(br.readLine()) % 42);
System.out.println(hs.size());
}
}
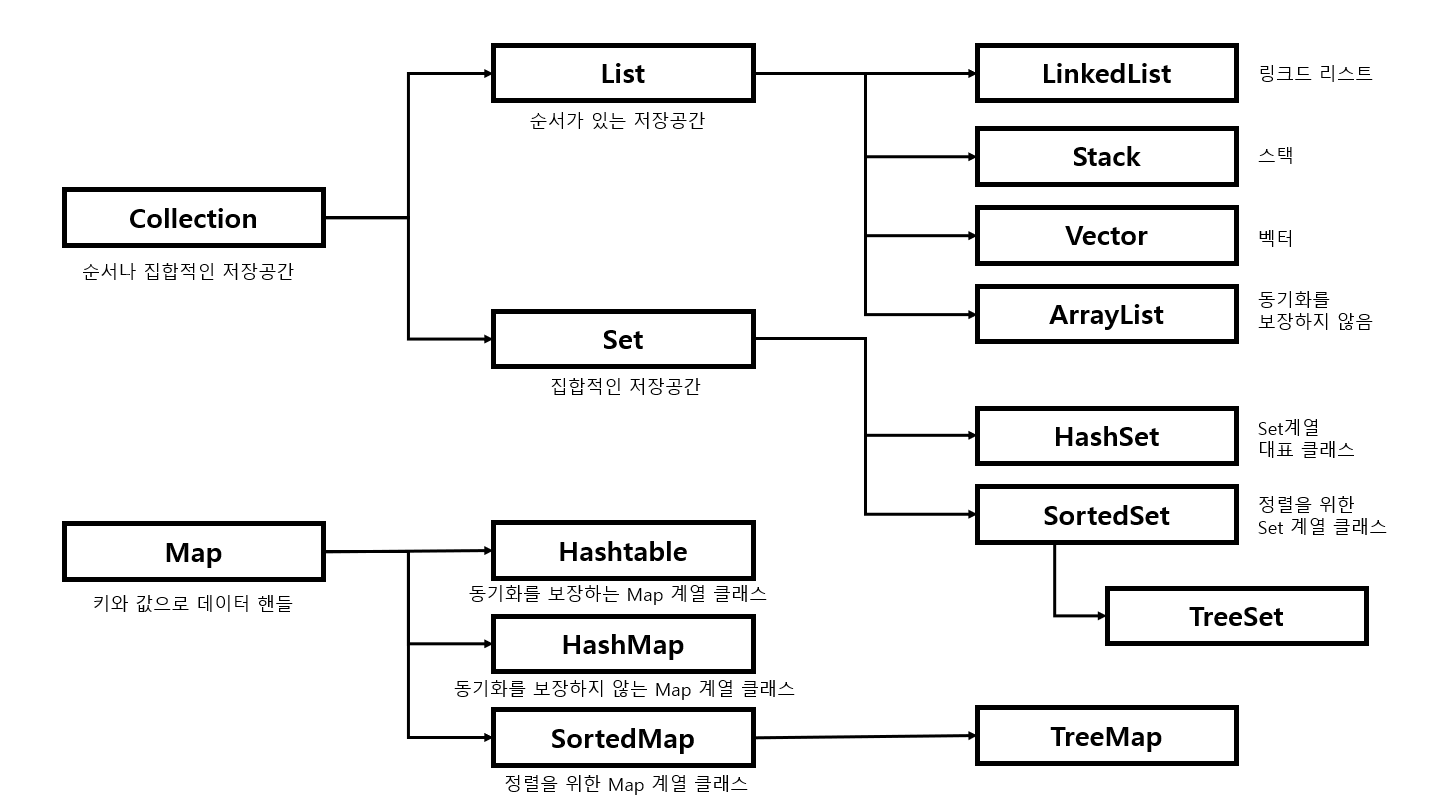
List, Map, Set에 관해 설명드리기 전에 컬렉션 프레임워크를 사용하는 이유에 대해 말씀드리자면, 기존에는 많은 데이터를 처리하기 위해 배열을 사용했었지만 크기가 고정되어있고 삽입 및 삭제 시간이 오래 걸린다는 불편한 점들이 많았습니다. 따라서 이를 보완하기 위해 자바에서 동적 배열 개념인 컬렉션 프레임워크를 제공하였는데 종류는 대표적으로 List, Map, Set이 있습니다. 그리하여 자바 컬렉션 프레임워크로 인해 자료의 삽입, 삭제, 검색 등등이 용이해지고 어떠한 자료형이라도 담을 수 있으며 크기가 자유롭게 늘어난다는 강점을 가져 많은 사람들에게 사용되고 있습니다.
| List
순서가 있고 중복을 허용합니다. 인덱스로 원소에 접근이 가능합니다. 크기가 가변적입니다.
List의 종류와 특징
LinkedList
양방향 포인터 구조로 데이터 삽입, 삭제가 빠르다.
ArrayList보다 검색이 느리다.
ArrayList
단반향 포인터 구조로 데이터 순차적 접근에 강점을 가진다.
배열을 기반으로 데이터를 저장한다.
데이터 삽입, 삭제가 느리다.
데이터 검색이 빠르다.
|Map
Key와 Value의 한쌍으로 이루어지는 데이터의 집합. Key에 대한 중복이 없으며 순서를 보장하지 않습니다. 뛰어난 검색 속도를 가집니다. 인덱스가 따로 존재하지 않기 때문에 iterator를 사용합니다.
Map의 종류와 특징
HashMap
Key에 대한 중복이 없으며 순서를 보장하지 않는다.
Key와 Value 값으로 NULL을 허용한다.
동기화가 보장되지 않는다.
검색에 가장 뛰어난 성능을 가진다.
HashTable
동기화가 보장되어 병렬 프로그래밍이 가능하고 HashMap 보다 처리속도가 느리다.
Key와 Value 값으로 NULL을 허용하지 않는다.
LinkedHashMap
입력된 순서를 보장한다.
TreeMap
이진 탐색 트리(Red-Black Tree)를 기반으로 키와 값을 저장한다.
Key 값을 기준으로 오름차순 정렬되고 빠른 검색이 가능하다.
저장 시 정렬을 하기 때문에 시간이 다소 오래 걸린다.
|Set
데이터의 집합이며 순서가 없고 중복된 데이터를 허용하지 않습니다. 중복되지 않은 데이터를 구할 때 유용합니다. 빠른 검색 속도를 가집니다. 인덱스가 따로 존재하지 않기 때문에 iterator를 사용합니다.
Set의 종류와 특징
HashSet
인스턴스의 해시값을 기준으로 저장하기 때문에 순서를 보장하지 않는다.
NULL 값을 허용한다.
TreeSet보다 삽입, 삭제가 빠르다.
LinkedHashSet
입력된 순서를 보장한다.
TreeSet
이진 탐색 트리(Red-Black Tree)를 기반으로 한다.
데이터들이 오름차순으로 정렬된다.
데이터 삽입, 삭제에는 시간이 걸리지만 검색, 정렬이 빠르다.
| 정리
List는 기본적으로 데이터들이 순서대로 저장되며 중복을 허용한다.
Map은 순서가 보장되지 않고 Key값의 중복은 허용하지 않지만 Value값의 중복은 허용된다.
9개의 서로 다른 자연수가 주어질 때, 이들 중 최댓값을 찾고 그 최댓값이 몇 번째 수인지를 구하는 프로그램을 작성하시오.
예를 들어, 서로 다른 9개의 자연수
3, 29, 38, 12, 57, 74, 40, 85, 61
이 주어지면, 이들 중 최댓값은 85이고, 이 값은 8번째 수이다.
입력
첫째 줄부터 아홉 번째 줄까지 한 줄에 하나의 자연수가 주어진다. 주어지는 자연수는 100 보다 작다.
출력
첫째 줄에 최댓값을 출력하고, 둘째 줄에 최댓값이 몇 번째 수인지를 출력한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws NumberFormatException, IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// StringTokenizer st = new StringTokenizer(br.readLine());
int[] arr = new int[9];
int max = 0;
int index = 0;
int N;
for (int i = 0; i < 9; i++) {
N = Integer.parseInt(br.readLine());
if (max < N) {
max = N;
index = i+1;
}
}
System.out.println(max);
System.out.println(index);
}
}
최댓값을 구하는 단순한 문제
배열에 입력값을 저장한 뒤 max 변수랑 비교했을 때 더 큰 값이 나올때마다 max에 저장 해주고
흔한 수학 문제 중 하나는 주어진 점이 어느 사분면에 속하는지 알아내는 것이다. 사분면은 아래 그림처럼 1부터 4까지 번호를 갖는다. "Quadrant n"은 "제n사분면"이라는 뜻이다.
예를 들어, 좌표가 (12, 5)인 점 A는 x좌표와 y좌표가 모두 양수이므로 제1사분면에 속한다. 점 B는 x좌표가 음수이고 y좌표가 양수이므로 제2사분면에 속한다.
점의 좌표를 입력받아 그 점이 어느 사분면에 속하는지 알아내는 프로그램을 작성하시오. 단, x좌표와 y좌표는 모두 양수나 음수라고 가정한다.
입력
첫 줄에는 정수 x가 주어진다. (−1000 ≤ x ≤ 1000; x ≠ 0) 다음 줄에는 정수 y가 주어진다. (−1000 ≤ y ≤ 1000; y ≠ 0)
출력
점 (x, y)의 사분면 번호(1, 2, 3, 4 중 하나)를 출력한다.
단순한 if문 문제다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int result = 0;
N = Integer.parseInt(br.readLine());
M = Integer.parseInt(br.readLine());
if (N > 0 && M > 0)
result = 1;
else if (N <0 && M > 0)
result = 2;
else if (N < 0 && M < 0)
result = 3;
else if (N > 0 && M < 0)
result = 4;
System.out.println(result);
}
}
(1)과 (2)위치에 들어갈 세 자리 자연수가 주어질 때 (3), (4), (5), (6)위치에 들어갈 값을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 (1)의 위치에 들어갈 세 자리 자연수가, 둘째 줄에 (2)의 위치에 들어갈 세자리 자연수가 주어진다.
출력
첫째 줄부터 넷째 줄까지 차례대로 (3), (4), (5), (6)에 들어갈 값을 출력한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int out1, out2, out3, res;
N = Integer.parseInt(br.readLine());
M = Integer.parseInt(br.readLine());
out1 = N * ((M % 100) % 10);
out2 = N * ((M % 100) / 10);
out3 = N * (M / 100);
res = N * M;
System.out.println(out1);
System.out.println(out2);
System.out.println(out3);
System.out.println(res);
}
}
StringTokenizer는 긴 문자열을 지정된 구분자를 기준으로 문자열을 슬라이싱하는데 사용된다. 100,200,300,400의 문자열을 , 구분자를 기준으로 슬라이싱하게 되면 4개의 문자열을 획득할 수 있다. StringTokenizer의 경우 단 한개의 구분자를 사용해야 한다는 단점이 있으므로 복잡한 형태의 구분자로 문자열을 나누어야 할 때는 Scanner나 split를 사용해야 한다. StringTokenizer 생성자 및 메소드는 다음 표와 같다.
생성자/메소드
설 명
StringTokenizer(String str, String delim)
문자열을 지정된 구분자로 나누는 StringTokenizer를 생성한다. 구분자는 토큰으로 간주되지 않음
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) {
String source = "100,200,300,400";
StringTokenizer st = new StringTokenizer(source, ",");
while (st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
}
}